









by Ismael Marín Carrión, Julio José Águila Guerrero, Enrique Arias Antúnez, María del Mar Artigao Castillo and Juan José Miralles Canals
Physicists and computer scientists from the University of Castilla-La Mancha are currently performing transdisciplinary work on nonlinear time series analysis. This research will analyse some important properties of time series, and will also provide a set of high performance algorithms that will allow this analysis to be made in a reasonable time, especially in real applications such as biomedicine or climate science in which real-time responses are required.
Many applications of science and engineering, eg in physics, biology, economics or meteorology, are determined by dynamical systems. These systems evolve across time and then generate a set of data spaced in time called time series. The analysis of time series from real systems, in terms of nonlinear dynamics, is the most direct link between chaos theory and the real world. Information that is very useful for making predictions over dynamical systems can be extracted by the analysis of these time series.
Since many of these applications must provide a real-time response, it is necessary that analysis and prediction be performed on a reasonable time scale. High performance computing gives a feasible solution to this problem, which enables it to be solved in an efficient manner. Nowadays, parallel computing is one of the most appropriate ways of obtaining important computational power.
This work is included in a transdiciplinary framework, within which are collaboratively working physicists, medical doctors and computer scientists from Real-Time and Concurrent Systems (RETICS) and the Interdisciplinary Research Group in Dynamical Systems (IRGDS) from the University of Castilla-La Mancha. This framework is intended to achieve an algorithmic solution of high performance for the computational problems that underlie nonlinear time series analysis.
We have explored several algorithms of nonlinear time series analysis, emphasizing the algorithms for computing the embedding dimension and the estimation of largest Lyapunov exponent of a dynamical system. These parameters play an essential role in the identification of chaos and prediction in time series data. The embedding dimension provides us with an approximate order of the dynamical system under study. From this parameter, we obtain the maximal Lyapunov exponent that is of special interest because it provides the horizon of predictability of the system, that is, the time within which we can make good predictions.
From a computational point of view, there are some algorithms in the literature that have been developed for computing these parameters, as well as many libraries. One of the most popular and widely used for the scientific community is the TISEAN package. It includes sequential implementations of methods of nonlinear time series analysis.
However, as far as the authors know, there exist no parallel implementations of the aforementioned methods. Thus, we have developed different parallel implementations based on distributed memory architectures, taking the TISEAN package as a starting point. The parallel implementations use the message passing paradigm, and particularly the MPI (Message Passing Interface) standard. This paradigm can be extended to shared and distributed-shared systems, and therefore the developed implementations can run in many diverse parallel computers. MPI basically provides interfaces to send/receive data and synchronize operations between the multiple tasks of a parallel application.
Three classical examples of discrete- and continuous-time chaotic systems, the Lorenz attractor, the Hénon map and the Rössler attractor, and two real cases, an ECG signal and a temperature time series have been considered as case studies in order to evaluate the goodness of the parallel implementation. The performance analysis of the parallel implementations carried out has shown that the execution time for applying both methods has been dramatically reduced because of the use of parallelism.

Figure 1: The Lorenz attractor.
The work presented here has two natural continuations. The first one consists in developing parallel implementations based on MPI+OpenMP. While often used in scientific models for shared memory parallelism on symmetric multi-processor (SMP) machines, OpenMP can also be used in conjunction with MPI to provide a second level of parallelism for improved performance on clusters having SMP compute nodes. Programs that mix OpenMP and MPI are often referred to as hybrid codes. Thus, this kind of parallel implementation is able to exploit the parallelism present in most modern parallel computers. Other future work is to drive the parallel implementations based on distributed memory architectures towards the framework of GPU (Graphics Processing Unit) architecture. The second natural continuation of this work consists in the study and analysis of complex networks and the development of appropriate software that can deal with real problems.
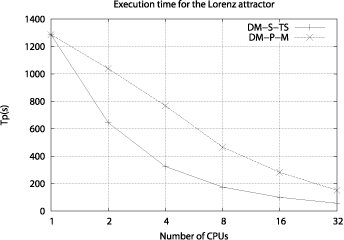
Figure 2: Execution time of the parallel implementations for computing the method of Kantz.
Please contact:
I. Marín Carrión, University of Castilla-La Mancha, Spain
Tel: +34 967 599 200
E-mail:
