









by Stephan Bongers (CWI)
Standard statistical guarantees fail when analysts repeatedly check incoming data. By integrating anytime-valid inference with reinforcement learning, this work enables safe policy evaluation under continuous monitoring.
Making safe decisions with predictable outcomes in an unknown environment is a longstanding goal in science. For example, in healthcare we want to predict treatment outcomes before giving the treatment, or in economics we seek interventions with reliable effects despite uncertainty. Although many off-the-shelf methods exist that test whether a policy has an outcome with a certain statistical guarantee provided that the sample size is fixed in advance, they generally break down when the decision maker is allowed to start and stop data collection at any point in time. By combining reinforcement learning and anytime-valid methods, we aim to develop such statistical methods that allow for safe decision making at any point in time.
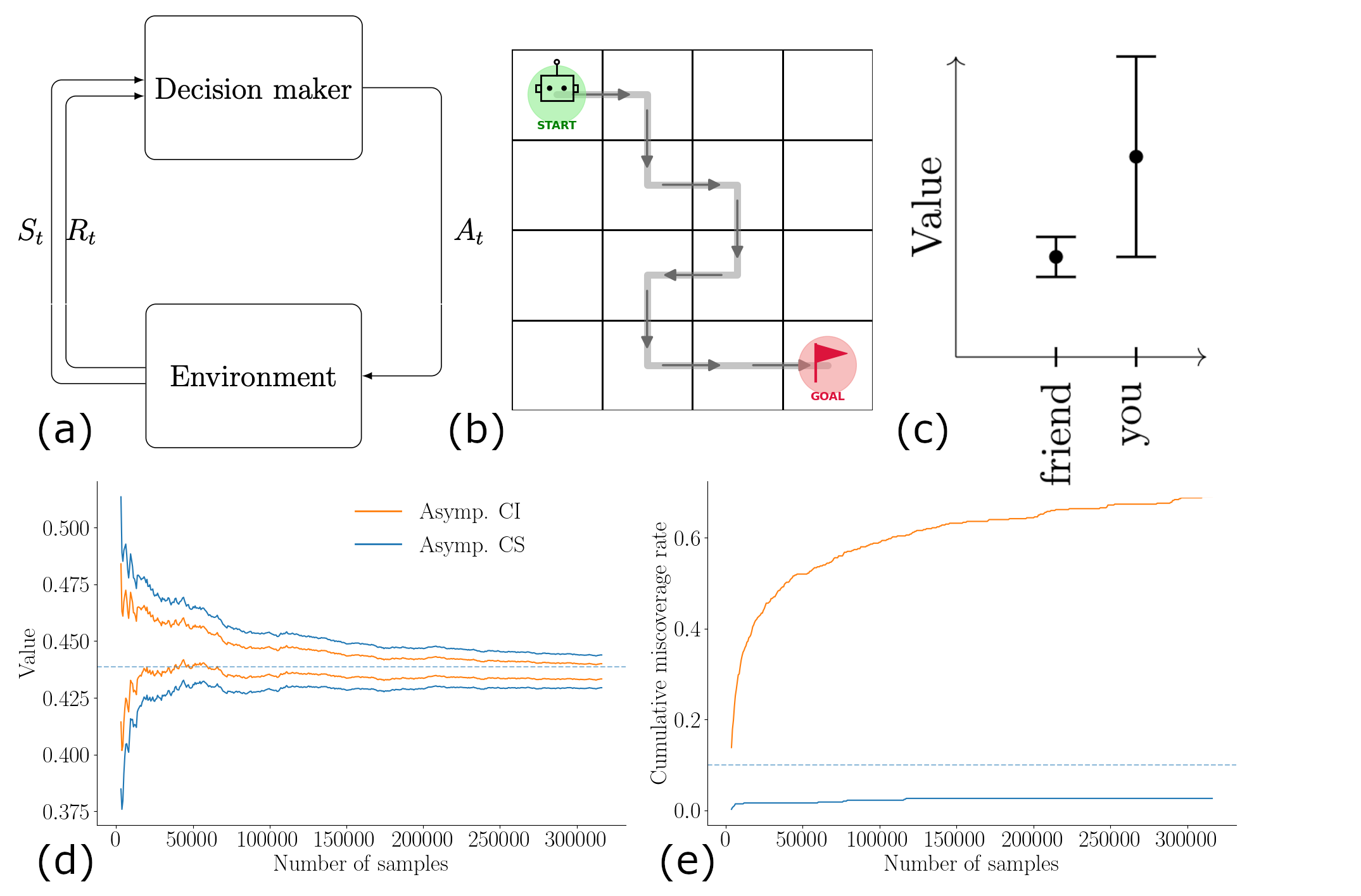
Reinforcement learning (RL) studies how a decision maker can learn a policy that maximizes long-term cumulative reward through interaction with an environment (see Figure 1(a)). When the environment is known, as in games like chess or Go, policies can be evaluated reliably by simulating many games. But in domains such as healthcare or economics, where the environment is not known beforehand, reliably evaluating new policies before deployment becomes much harder.
Off-policy evaluation (OPE) aims to estimate the value of a policy of interest, known as the target policy, using data collected under a different policy, referred to as the behavior policy. A major challenge in OPE is the curse of horizon: as the decision horizon increases, the overlap between the target and behavior policies can decay exponentially fast. This diminishing overlap severely undermines the reliability of value estimation. Consequently, many practical applications require not only accurate point estimates but also principled measures of uncertainty, such as confidence intervals (CIs). In response to this need, a growing body of work has developed OPE methods for constructing statistically valid CIs [2].
Consider the following example. Suppose you have access to the gameplay records of a friend who plays the Gridworld game every day (see Figure 1(b)). Can you determine, with certainty, whether you could play the game better than your friend? One possible approach is to compute confidence intervals (CIs) with some existing OPE method for both your friend’s strategy and your own hypothetical strategy using the n games observed so far. Although your strategy may appear more promising, the resulting CIs may still be inconclusive because they overlap (see Figure 1(c)). At this point, it may seem natural to collect additional gameplay data and check again whether the comparison becomes conclusive. However, doing so invalidates the CIs, since the sample size would then depend on the observed data. To avoid this issue, the sample size must be fixed independently of the results. Consequently, we cannot reuse the first n samples to draw a new conclusion. Instead, any further inference must rely on a newly collected set of gameplay records that is independent of the initial n games.
This example illustrates an important limitation: the CIs are only valid at some non-data dependent sample size. Any inference made at a data-dependent stopping time (e.g., under continuous monitoring) invalidates the statistical guarantee. This limitation becomes even more apparent for asymptotic CIs that require large prespecified sample sizes, especially when the collection of data is expensive. Asymptotic CIs are central limit theorem-based CIs which are only approximately valid for large sample sizes and have the advantage that the intervals are approximately valid under weaker modeling assumptions.
Rather than relying on asymptotic confidence intervals (CIs), we consider the recently developed notion of asymptotic confidence sequences (CSs), which retain their validity under arbitrary data-dependent stopping times [3]. In other words, asymptotic CSs provide anytime-valid uncertainty quantification. A key advantage of asymptotic CSs is that they enable continuous monitoring of the estimates while allowing additional data to be collected adaptively. Although non-asymptotic CSs have long been studied in the statistics literature, their applicability to general reinforcement learning settings is often limited by restrictive assumptions required for validity.
We derived asymptotic CSs for the general RL setting [1]. In Figure 1(d) we compare the CS and CI at several sample sizes for the Gridworld example. We see that the CI did not cover the true value at several sample sizes. Figure 1(e) shows the cumulative miscoverage rate, i.e., the probability of failing to capture the true value at any sample size up to n. The cumulative miscoverage rate is estimated by repeating the experiment in Figure 1(d) many times. In contrast to the asymptotic CI, we see that the miscoverage rate of the asymptotic CS is bounded uniformly over the sample sizes by the Type-I error rate.
Our research demonstrates that it is possible to make safe decisions with predictable outcomes in unknown environments while continuously monitoring incoming data without inflating the Type-I error rate. This paves the way toward truly safe reinforcement learning, where data collection under a current policy can be terminated as soon as there is sufficient statistical evidence that an alternative policy performs better. By enabling anytime-valid uncertainty quantification throughout the decision process, carefully designed policies can support more reliable and trustworthy decision-making.
References:
[1] S. Bongers, F. A. Oliehoek, and M. T. J. Spaan, “Asymptotic anytime-valid off-policy evaluation for reinforcement learning,” work in progress, 2026.
[2] N. Kallus and M. Uehara, “Efficiently breaking the curse of horizon in off-policy evaluation with double reinforcement learning,” Operations Research, vol. 70, no. 6, pp. 3282–3302, 2022.
[3] I. Waudby-Smith, D. Arbour, R. Sinha, E. H. Kennedy, and A. Ramdas, “Time-uniform central limit theory and asymptotic confidence sequences,” Annals of Statistics, vol. 52, no. 6, pp. 2613–2640, Dec. 2024.
Please contact:
Stephan Bongers
CWI, The Netherlands

