









by Adrienne Tuynman and Timothée Mathieu (Univ. Lille, Inria, CNRS, Centrale Lille, UMR 9189 – CRIStAL)
Political polls before elections are useful to identify promising candidates, and to allow parties to make compromises or build alliances. We are interested in conducting polls sequentially, so that one can stop acquiring data as soon as possible while safely yielding statistically significant results.
While many countries use uninominal voting for their elections, where voters only choose the name of their preferred candidate, alternative comparison-based systems are seeing more and more usage, especially in smaller organisations or on the local scale. In those systems, voters give a ranking of candidates, so that their opinions are better taken into account. In this setting, how can one efficiently conduct an opinion poll? We propose to use sequential e-values for this purpose.
Sequential Hypotheses Testing for Political Surveys
We are looking into the Borda system: with N candidates, each voter awards 0 points to their least liked candidate; the one slightly better gets one point; all the way up to the preferred candidate, who gets N-1 points. After tallying up the total number of points that each candidate gets, the one with the most points wins. A candidate that is well liked by a majority of the population could therefore beat a candidate that is more polarising.
Formally, we assume the existence of a preference matrix, noting for each pair of candidates which one was preferred. The preference of i over j is represented by a Bernoulli random variable, of parameter equal to the probability that i is preferred to j. The theoretical Borda score can be computed through the matrix of these parameters, where the theoretical score of i is the sum over j of the probability that i beats j. At each iteration, we collect one sample from each of those Bernoulli random variables, thus yielding an observation of size N(N-1)/2.
We want to test which candidate wins an election determined by this unknown preference matrix. To be able to stop our survey as soon as possible, we use sequential e-values, allowing for optional stopping of the testing process.
E-values and Reverse Information Projection
Formally, this means we test simultaneously for each candidate i the hypothesis H0,i: “i is a Borda winner” against H1,i, “i is not a Borda winner”.
A classical construction of e-values is based on the likelihood ratio. From [1], at the numerator, we use an estimate of the alternative distribution using the posterior distribution. On the denominator, we compute a projection p0 of this posterior distribution onto H0 via Reverse information projection, a projection that minimises the Kullback-Leibler divergence.
Formally, this yields
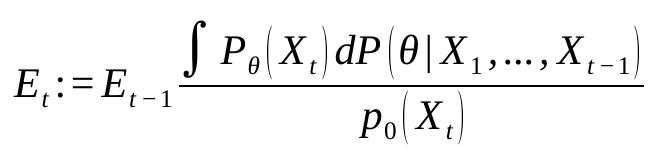
For simplicity, the prior is a product of Jeffrey priors, which makes the posterior distribution easy to compute. Due to the multiplicative form of this e-value, we have the optional stopping property: we can stop collecting data whenever we want for whatever reason. The test which rejects H0 if the e-value is larger than 1/α has type I error below α. This describes how to test if a given candidate is a Borda Winner; to find the Borda Winner we use parallel tests as in [2], Section 3.2, which controls the probability of selecting a non-winner.
Application to sequential testing for Borda Winner in 2022 French Presidential Elections
We apply this method to a dataset of opinions about the 2022 French Presidential Elections from [L1]. This dataset provides pairwise votes coming from 2287 French voters, collected before and after the first round of the presidential elections. The responders also provided the ballot they actually cast in the official elections, and we use this actual ballot to reweight the sampling in order to match the official electoral results, in the same way that the original survey did.
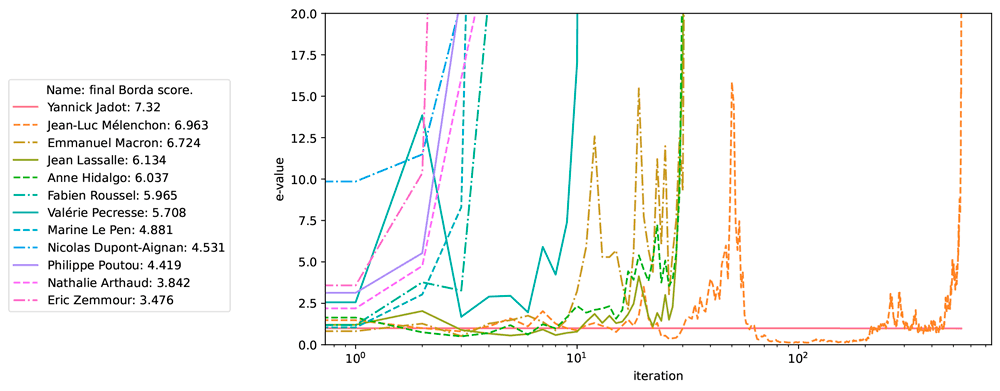
At each timestep, for each pair of candidates, we sample a duel between those two. For each candidate, we try to reject the hypothesis that they are a Borda winner, with type I error 5%. Based on that, we plot in Figure 1 the e-value corresponding to each candidate, depending on the number of iterations. When two candidates i and j are eliminated, it is no longer necessary to sample the preference i versus j, thus reducing the number of samples per iteration. In the end, only one candidate, Yannick Jadot, remains; the dataset confirms that he is the theoretical Borda winner. Interestingly, his e-value remains equal to 1 because the empirical distribution always lies within the hypothesis set corresponding to Jadot being a Borda winner. Consequently, no evidence accumulates against that hypothesis.
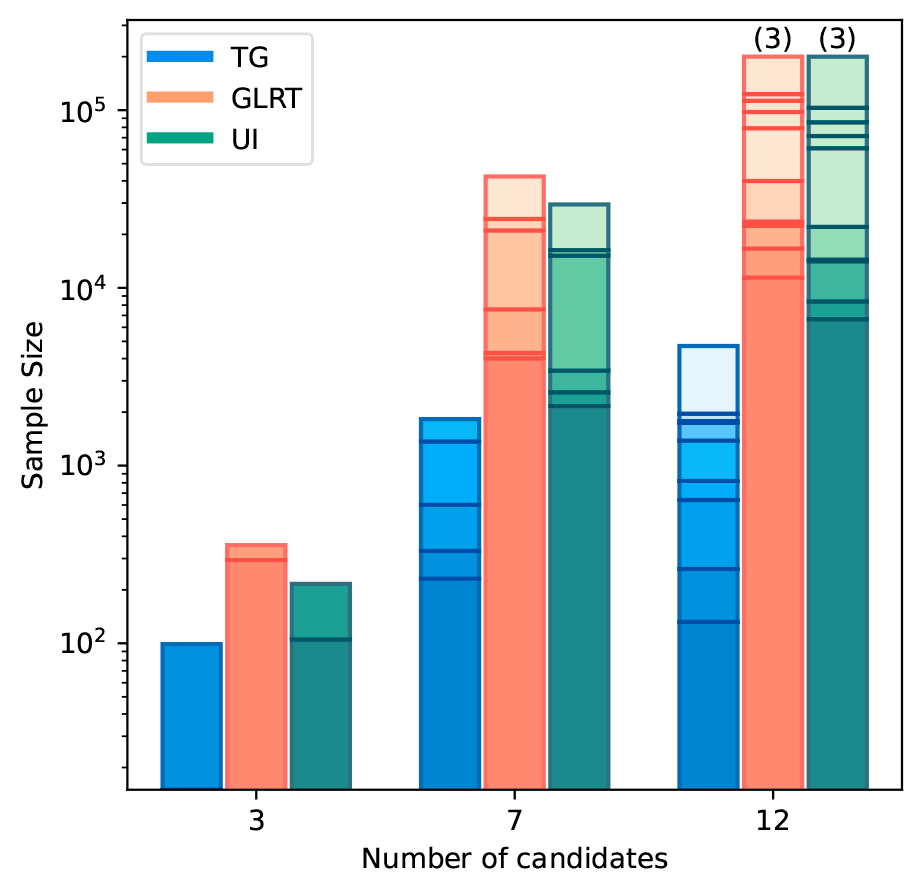
In Figure 2, we plot the number of samples required to retain only one potential winner, comparing our test (denoted TG) to two baselines: Universal Inference (see [3] Section 7), and the GLRT test (from [2] Section 3.2). We stop after collecting 2x105 samples, and - if the test hasn't yet yielded a single winner - we give the number of candidates still not rejected by the end of sample collection. Note that, while the number of samples seems to increase with the number of candidates, it is not always that straightforward: adding a very dominant candidate to a pool of equivalent candidates will make the test easier. Still, in those simulations, the e-value based test manages to conclude quicker than our two baselines, especially so as the instance gets more costly. For reference, official political surveys (IPSOS) conducted prior to the 2022 election used a total of 7,321 voters, in contrast TG uses 171 voters for a sample size of 4721 pairwise comparisons.
Our proposed e-values give a flexible and efficient way to do a political poll, allowing for optional stopping and using fewer samples than what is typically used in such surveys while having strong statistical guarantees.
Link:
[L1] https://doi.org/10.5281/zenodo.10998451
References:
[1] R. J. Turner and P. D. Grünwald, “Exact anytime-valid confidence intervals for contingency tables and beyond,” Statistics & Probability Letters, vol. 198, p. 109835, 2023.
[2] E. Kaufmann, Contributions to the Optimal Solution of Several Bandit Problems. HDR dissertation, Université de Lille, 2020.
[3] L. Wasserman, A. Ramdas, and S. Balakrishnan, “Universal inference,” Proceedings of the National Academy of Sciences, vol. 117, no. 29, pp. 16880–16890, 2020.
Please contact:
Timothée Mathieu
Inria, France

