









by Stan Koobs and Nick W. Koning (Erasmus University Rotterdam)
A classical statistical problem is to assess whether an unknown quantity is negligible: that is, practically equivalent to zero. It is standard to define ‘negligible’ as being smaller in magnitude than some threshold margin. Specifying this margin has plagued statisticians for decades: if it is set too large, then one can hardly speak of negligibility, but if the margin is set too small, then one may need an enormous amount of data to statistically establish negligibility. In recent work, we study this problem in depth and show how e-values can be used to bypass it, by enabling one to select the margin post-hoc: after seeing the data.
Many important decisions hinge on showing that some unknown quantity is negligible: a cheaper medical treatment is approved when its effect is close enough to the established treatment; the existence of a psychological effect may be called into question if a replication study shows the effect is negligible; a product feature is removed if an A/B test shows that it hardly improves customer engagement.
Establishing negligibility is traditionally framed as a hypothesis testing problem, commonly known as equivalence testing or non-inferiority testing. In this framework, the statistician first selects an equivalence margin: a threshold below which the quantity of interest is considered negligible. They then test the hypothesis that the quantity exceeds this margin. If this hypothesis is rejected, the quantity is declared to be negligible. This testing framework has become the standard tool for establishing negligibility, and is embedded in FDA, EMA, and ICH guidelines.
Unfortunately, the use of an equivalence test to establish negligibility faces a longstanding problem: such tests require the statistician to specify a margin, yet in many applications there simply is no natural margin below which a quantity is practically negligible and above which it is substantive. A common “solution” is to defer the choice of margin to an expert or to standard convention. But while this gives the statistician a usable margin, it does not solve the underlying problem: if there truly is no natural margin, then no expert or convention can make one appear.
If we do proceed with selecting a margin in an application where no natural margin exists, we are faced with a difficult trade-off: set it too large and the verdict of “negligible” becomes weak; set it too small and even a genuinely negligible quantity may demand an impractical amount of data to establish this. It may then be tempting to choose the margin post-hoc, based on the data, but this renders the statistical test invalid.
All of this leads to a natural question: should establishing negligibility really be treated as testing a single hypothesis?
This question is at the heart of our recent paper [1]. To answer it, we take a step back to consider the role of statistics within an application. We argue that its primary role is to provide statistical guarantees on the consequences of decisions, which can subsequently be used to inform decision makers. Reasoning backwards from these guarantees, we can determine the appropriate statistical methodology.
The underlying desire to show that the unknown quantity is negligible can be interpreted to mean that larger values of this quantity correspond to worse consequences. Under this natural assumption, we find that the appropriate methodology is not to report a single test outcome but a test outcome for every margin. The margins corresponding to hypotheses that are not rejected jointly form a confidence set for the unknown quantity, as shown in Figure 1. Only if the consequences hinge on a single margin, then a single equivalence test for this natural margin suffices.
We take this one step further by generalizing beyond hypothesis tests to e-values, reporting an e-value against every margin simultaneously. The result is what we call an equivalence curve, of which an example is shown as the solid line in Figure 1. It provides a continuous record of how much evidence the data carries against each margin. The larger the margin, the easier it is to establish that the unknown quantity is below it, so that the curve rises with the margin. For comparison, the dashed line shows the special equivalence curve that is built out of tests. This curve is very rigid, as tests are binary e-values that emit either no evidence (no rejection) or some large amount of evidence (rejection).
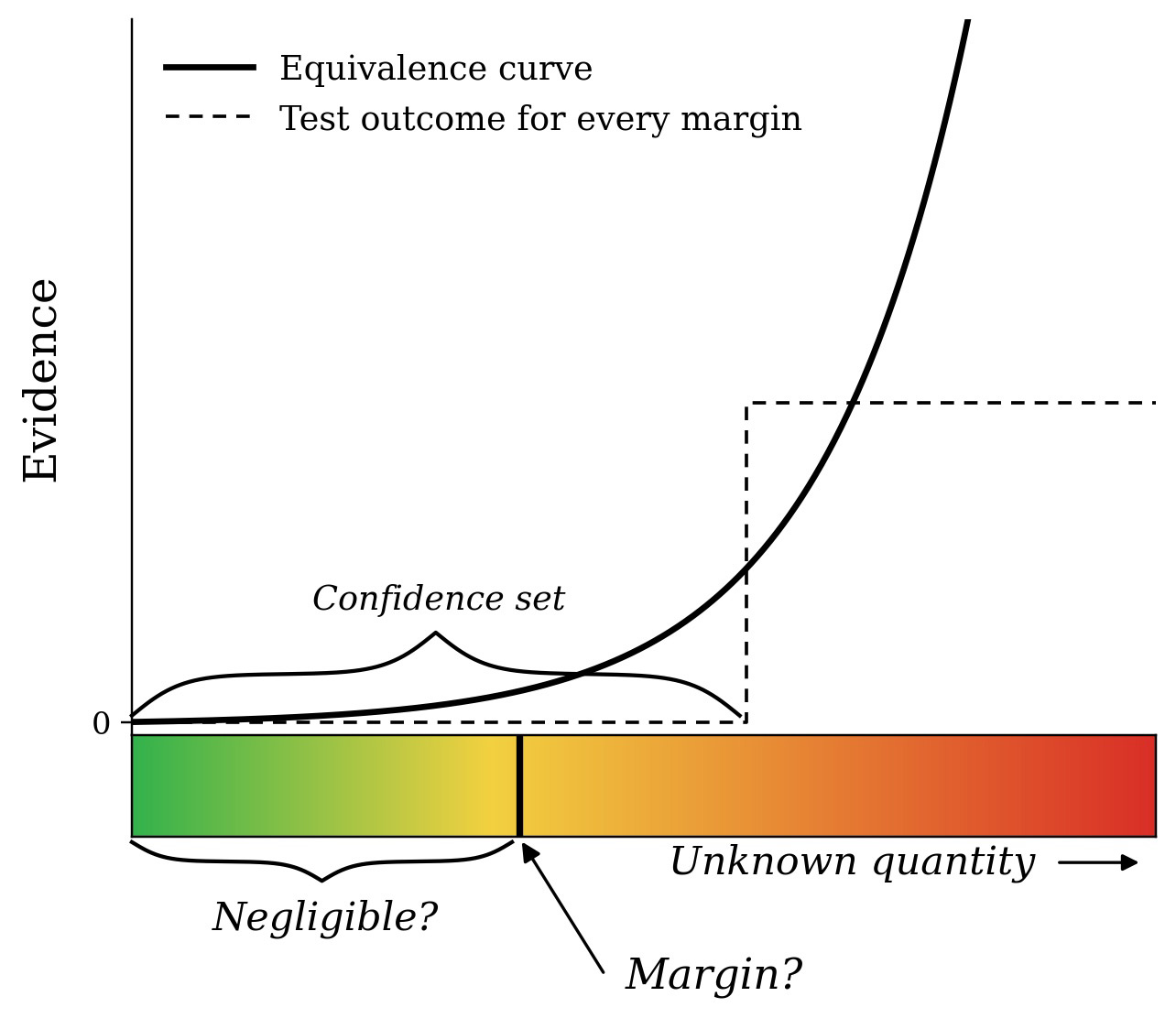
A remarkable feature of the equivalence curve is that it is simultaneously valid for every margin, allowing one to browse the equivalence curve and select a margin post-hoc while maintaining statistical validity. This means we can truly bypass the problem of pre-selecting a margin. This builds on recent work about hypothesis testing with a data-dependent significance level by Grünwald [2] and Koning [3], by implicitly coupling the margin to the significance level.
Taking a step back, a more general message that underlies our work is that not every statistical question must be forced into testing a single hypothesis. Establishing negligibility is a clean example: the real difficulty was never how to choose the right equivalence margin, but whether the problem should be reduced to testing a single margin in the first place.
References:
[1] S. Koobs, N. W. Koning, “Equivalence testing with data-dependent and post-hoc equivalence margins”, arXiv:2603.16213, 2026.
[2] P.D. Grünwald, “Beyond Neyman–Pearson: E-values enable hypothesis testing with a data-driven alpha”, PNAS 121(39):e2302098121, 2024, https://doi.org/10.1073/pnas.2302098121
[3] N. W. Koning, “Post-hoc α hypothesis testing and the post-hoc p-value”, arXiv:2312.08040, 2025.
Please contact:
Stan Koobs
Erasmus University Rotterdam, The Netherlands
Nick W. Koning
Erasmus University Rotterdam, The Netherlands

