









Modern software development commonly makes use of a multitude of software repositories. How can these help us to understand the on-going development process? Researchers of Eindhoven University of Technology design new methods revealing how software has been developed.
Modern software development commonly makes use of various configuration management systems, issue tracking systems, automated quality control and testing systems. Analysis of data in the repositories can give valuable insights into the development process of legacy systems. For example, it can answer the following software engineering questions: is the project development documentation kept up-to-date with the implementation? How fast are bugs resolved and feature requests implemented? Which (groups of) developers are responsible for the introduction of bugs or overtly complex code and code that does not meet company-specific and/or industry guidelines and standards such as MISRA? When and where have particular standard violations been introduced and (how) are they related to later discovered bugs? If there is no relationship, is it worth narrowing the scope of routine quality checks to the actually important ones? What is the share of software artifacts covered by tests and how does this share change in time (eg from version to version) and project space (from subsystem to subsystem or one developer group to another)?
In the on-going project at Eindhoven University of Technology, we design a generic framework that allows the user to choose repositories, as well as analysis techniques depending on the software engineering question at hand. This is in sharp contrast with many existing repository mining approaches that consider a single specific question (eg which developers are responsible for introduction of bugs) or one specific kind of repository or group of repositories (usually a version control system or a version control system together with the bug tracker).
To create the generic framework we need to separate the preprocessing step, consisting of choosing and combining different repositories, from the analysis and visualization step. The first step takes care of specific challenges pertaining to the presence of multiple repositories, such as matching identities of developers and artifacts mentioned across different repositories, as well as synchronization of the time stamps. This step is carried out by a tool called FRASR. FRASR extracts from various data sources such as version control systems, bug trackers, mail archives, news groups, Twitter messages or issue reports, and combines this information in one log file. Given the log file, the second step implements a broad spectrum of analysis and visualization techniques supporting the user in answering the software engineering question. To implement the second step we make use of the existing work on process mining and ProM, a generic open-source framework for implementing process mining tools. Process mining aims at discovering, analyzing and visualizing business process models given a log of an information system. We stress that decoupling log preprocessing (FRASR) from the actual mining (ProM) makes a broad spectrum of analysis and visualization techniques readily available, and creates a highly flexible platform for application of repository mining.
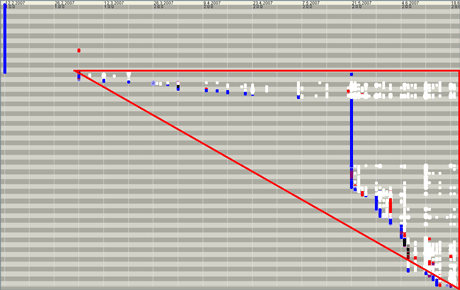
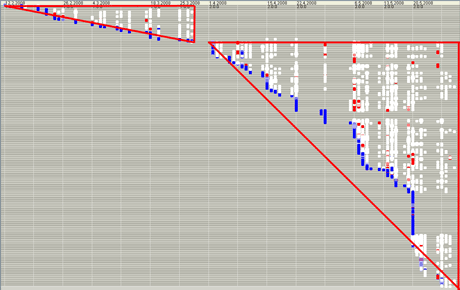
Figure 1: Visualizations of FRASR+ProM: the horizontal axes represents time, lines correspond to files, colored spots indicate events pertaining to the files such as creation (blue), modification (white) and deletion (red). Big red triangles have been added for readability purpose. The figure on the top shows only one triangle starting at the beginning of the project, ie, despite the prescribed development guideline, the prototype has been reused in the final implementation. The figure on the bottom shows two triangles: the triangle on the top corresponds to the prototype, the triangle on the bottom corresponds to the final implementation, ie, software development adhered to the prescribed guideline.
We have successfully applied process mining software repositories to study a number of open-source software systems and student projects. We have considered such aspects of the development process as roles of different developers and the way bug reports are handled. In student projects we have focused on investigating whether the students adhered to the prescribed software development process. Using FRASR+ProM combination we have produced the following visualizations. For one of the projects the visualization clearly shows two triangles corresponding to the prototype implementation and the final implementation. For another project the visualization shows one triangle starting from the beginning of the project and continuing throughout, ie the prototype was reused as part of the final implementation delivered to the customer.
Process mining of software repositories provides a solid basis for prediction-based analysis. While the preceding questions aimed at providing insights into the way software and related documents have evolved so far, prediction-based analysis focuses on providing insights into the way software and related documents can or will evolve in the future. We consider developing appropriate prediction techniques as an important direction of the future work.
Process mining of software repositories is a novel promising approach that allows developers, designers and managers to rapidly gain insights in the way the development process is progressing, obstacles it is facing and challenges it has to address.
Link:
http://www.frasr.org/
Please contact:
Alexander Serebrenik, Eindhoven University of Technology,
The Netherlands
Tel: +31 402473595
E-mail:
