








by Thanh Thoa Pham Thi, Juan Yao, Fakir Hossain
and Markus Helfert
High quality data helps the data owner to save costs, to make better decisions and to improve customer service and thus, information quality impacts directly on businesses. Many tools for data parsing and standardization, data cleansing, or data auditing have been developed and commercialized. However identifying and eliminating root causes of poor IQ along the information life cycle and within information systems is still challenging. Addressing this problem we developed an innovative approach and tool which helps identifying root causes of poor information quality.
In a recent survey by Gartner information quality (IQ) related costs are estimated as much as millions of dollar (SearchDataManagement.com, “Poor data quality costing companies millions of dollars annually”, 2009.). Meanwhile Thomson Reuters and Lepus survey in 2010 (http://thomsonreuters.com/content/press_room/tf/tf_gen_business/2010_03_02_lepus_survey) revealed “77% of participants intend to increase spending on projects that address data quality and consistency issues” which are “key to risk management and transparency in the financial crisis and the market rebuild”.
In order to improve and maintain IQ, effective IQ management is necessary, which ensures that the raw material (or data) an organisation creates and collects is as accurate, complete and consistent as possible. Furthermore the information product which is manufactured from raw data by transforming, assembling processes must also be accurate, complete and consistent. Thereby IQ management usually involves processes, tools and procedures with defined roles and responsibilities.
Total IQ Management is a cycle within 4 phases. The defining phase aims to define characteristics of information products and involved raw data, define IQ requirements for that information. The measuring phase focuses on IQ assessments and measurement against IQ requirements based on metrics such as data accuracy, completeness, consistency and timeliness. The result of this phase is analyzed in the analyzing phase which provides organizations with causes of errors and plans or suitable actions for improving IQ. The improving processes are taken place in the improving phase.
Many tools and techniques have been developed in order to measure the consistency of data, mostly involving some forms of business rules. Current approaches and tools for IQ auditing and monitoring often validate data against a set of business rules. These rules constrain the data entry or are used to report violations of data entries. However, the major challenge of these approaches is the identification of business rules, which can be complex and time consuming. Although simple rules can be relatively easy identifies, dynamic rules along business processes are difficult to discover.
Funded by Enterprise Ireland under the Commercialization programme, our research at the Business Informatics Group at Dublin City University focuses on addressing those challenges. A recent project -InfoGuard- aims to indentify and design business rules by combining business processes and data models. This project complements our already established rule-based data analyzing module for discovering root causes of data errors by indicating involved processes and involved organizational roles.
Our approach is based on business process documentation and data models extracted from legacy systems. The principles of our approach are to analyze rules based on the consistency between business process, data and responsibilities of organizational roles. Therefore, apart from business rules set out by the organizations, we can help users to identify IQ rules which come from correlations between business processes and data, particularly dynamic rules, and authority rules on data and business process performing. In other words, this approach makes clear the imprecision of the data model regarding to the business process model and vice-versa which are root causes of errors at the system specification level.
One of the most powerful features of our approach/tool is to support the rule identification by relating graphically business processes and data models. Business process elements and data elements concerning a rule are highlighted as long as designing/displaying the rule. By this way, the context and the rational of a rule is presented, which facilitates the rule management.
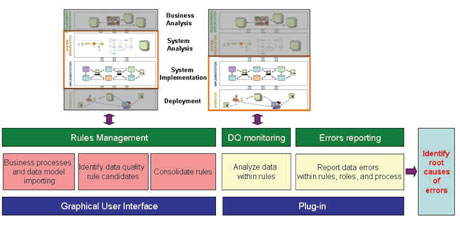
Figure 1. InfoGuard architecture.
Once IQ rules are obtained and stored in a rule repository, the analyzing service can be called to detect incorrect data. The tool then produces error reports after analyzing process. The report includes incorrect data, the involved rules, the involved process and the involved organizational roles. Figure 1 illustrates the architecture of our approach.
In the future we will apply our approach to a broader scale of applications such as rules across applications, across databases. We will need data profiling across databases for total data quality analyzing.
Link: http://www.computing.dcu.ie/big
Please contact:
Markus Helfert
School of Computing
Dublin City University
E-mail: