









by Eugenio Clerico (University of Oxford)
While e-values and p-values are often presented as competitors, they share deep structural connections. We highlight a functional perspective linking the two, and suggest how it might lead to new ways of translating p-value methods into the e-value framework.
P-values are probably the most widespread tool for hypothesis testing. A p-value is a number that summarises the data: a small value indicates that the observed data are unlikely under the null hypothesis. This provides a simple way to proceed: the null is rejected if the p-value is small enough. Yet, p-values are fragile objects that need to be handled with care. Their validity comes with prescriptions… For instance, the experimental setup (dataset size, significance level) must be fixed in advance, and cannot be changed on the fly as data arrive.
E-values are a more flexible counterpart to p-values, designed to overcome these practical limitations. An e-value is again a number summarising the data, but chosen so that its expectation under the null is at most one. A valid test is obtained by rejecting the null hypothesis if the e-value exceeds a given threshold. Intuitively, e-values directly represent evidence against the null hypothesis. E-values are typically easier to merge across different experiments than p-values, and they can be updated adaptively as data arrive, allowing the experiment to be stopped at any time.
The relationship between e-values and p-values is often presented as a rivalry, framed mostly in terms of contrast. Yet, once the testing problem is fixed, they are structurally similar objects. In both cases, they represent realisations on the observed data of random variables valued in [0,∞], typically called p-variables and e-variables. (Although p-values are usually defined in [0,1], extending them to [0,∞] does not affect the test.) An α-level test based on a p-variable P rejects whenever the observed p-value is at most α, while an α-level test based on an e-variable E rejects whenever the observed e-value is at least 1/α. Choosing P = 1/E (which can be shown to define a valid p-variable) yields a p-value procedure with exactly the same rejection rule as the e-value-based test.
So, are e-values just p-values? Well… In a way, e-values are some p-values. For a fixed data space and null hypothesis, we can take any e-variable E and associate with it its reciprocal 1/E, a p-variable with the same rejection rule as the original e-variable. Thus, there is a canonical e-to-p map. Yet, this map is not surjective: its image is a strict subclass of p-variables (see Figure), consisting only of those P for which 1/P is valid as an e-variable. [1] refers to the members of this subset as post-hoc p-variables, emphasising that their significance level can meaningfully be chosen after observing the data. In summary, an e-value test can be canonically identified with a p-value test, while the converse is in general not true, which is the price paid for the extra flexibility of e-value testing.
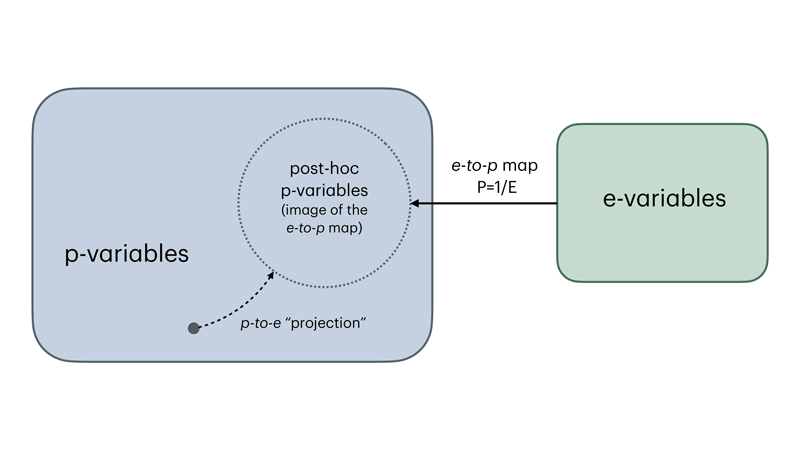
The connection between p-values and e-values is of course well known. However, it is usually formulated at the level of observed values, through calibrators: maps from [0,∞] to [0,∞] turning e-values into p-values (or conversely p-values into e-values) in a universal way that works uniformly for all possible null hypotheses [2]. Here we take a different viewpoint. Once the data space and the null hypothesis are fixed, p-variables and e-variables are functions on the same space, and one can ask how these classes of functions relate to each other. In the e-to-p direction, the distinction disappears: applying the reciprocal transformation to an observed e-value is the same as applying it pointwise to the whole e-variable. However, the p-to-e direction is different: an arbitrary p-variable cannot simply be inverted to obtain an e-variable. P-to-e calibrators provide universal numerical transformations from p-values to e-values. Yet, their universality comes with a loss of power, since they cannot exploit the specific structure of the given null hypothesis.
The functional viewpoint suggests a different direction, which (to my knowledge) remains largely unexplored. Since e-variables canonically correspond to a strict subclass of p-variables, one may ask whether any p-variable can be somehow “projected” onto this subclass. Such functional p-to-e conversion would be local (rather than universal), depending on the given data space and null hypothesis. Ideally, it should leave post-hoc p-variables unchanged (so that no power is lost when the p-variable already comes from an e-variable) and preserve the ordering of evidence (smaller p-values map to larger e-values). Finding a canonical principled way to define such “projections” might be challenging, yet these transformations could provide a useful bridge between p-values and e-values, helping translate existing p-value methods into the e-value framework without relying only on universal calibration.
E-values are just p-values is surely not an appealing slogan and would not do justice to the practical usefulness of e-values. The usual presentation remains the most natural one: defining e-values through their expected value is simple, direct, and well suited to the flexible procedures for which they were introduced. Yet, my aim is to recall a complementary interpretation and stress that working with e-values does not require leaving the p-values world behind. Rather, it means restricting attention to a subclass of p-values, characterised by stronger validity requirements, which make optional stopping, merging of evidence, and post-hoc interpretation possible. Hence, e-value theory should not be seen as discarding p-values, but as specialising p-value theory to make stronger forms of flexibility valid.
References:
[1] N. W. Koning, “Post-hoc α hypothesis testing and the post-hoc p-value,” arXiv preprint, 2023.
[2] V. Vovk and R. Wang, “E-values: Calibration, combinations and applications,” The Annals of Statistics, vol. 49, no. 3, pp. 1736–1754, 2021.
Please contact:
Eugenio Clerico
Department of Statistics, University of Oxford, UK

