









by Vaidehi Dixit (University of Nottingham) and Ryan Martin (North Carolina State University)
Good e-processes can be constructed for testing a specific null hypothesis against a specific alternative, but general inference need not have a specific alternative in mind. In such cases, one might seek an alternative hypothesis-agnostic e-process with fast growth rate under a wide range of alternatives. Our predictive recursion-based e-process construction offers just that, along with some deeper insights related to “objective” empirical probability.
E-processes are a hot topic in the modern statistics, machine learning, and data science landscape, thanks to their strong frequentist reliability properties, namely, anytime validity. But e-processes actually have a rather long history. Indeed, Neyman & Pearson constructed e-processes in their landmark paper on hypothesis testing and, likewise, Jeffreys advocated for the use of Bayes factors which, in certain cases, are e-processes. What these two seemingly different approaches have in common is that their respective e-processes correspond to likelihood ratios, and this connection between e-processes and likelihood ratios has been established in increasing generality in recent years [1, 2]. Roughly, this likelihood ratio has a numerator and denominator corresponding to the “best representatives” of the evidence of the alternative and null hypothesis, respectively. For example, in the classical Neyman--Pearson case where the null and alternative hypotheses are simple, these “best representatives” are trivial, namely the corresponding probability distributions. More formally, for a general composite null versus a composite alternative hypothesis, constructing these “best representatives” is more challenging; see the above references for details.
The e-process constructions just described are tailored to a particular testing problem, i.e., given null and alternative hypotheses. In the Fisherian spirit of probing the data for “significant” explanations that warrant further exploration, as opposed to formally testing a null against a specified alternative, one might ask if there is a generic or “alternative-hypothesis agnostic” e-process. Like with the universal inference framework of Wasserman, Ramdas, and Balakrishnan, we can assume that candidate explanations determine the denominator of the e-process likelihood ratio, hence only the numerator likelihood needs to be specified. Since a likelihood can be factored as a product of successive predictive distributions, i.e., the distribution of data point Xk, given X1, ..., Xk−1, for k = 1, ..., n, this boils down to specification of a forecasting system. Many forecasting systems are possible, but an essential requirement is that it be flexible enough to adapt to data produced by any one of a wide collection of possible “true distributions”. A secondary requirement is that the predictive distribution can be updated efficiently given a previous predictive distribution and new data.
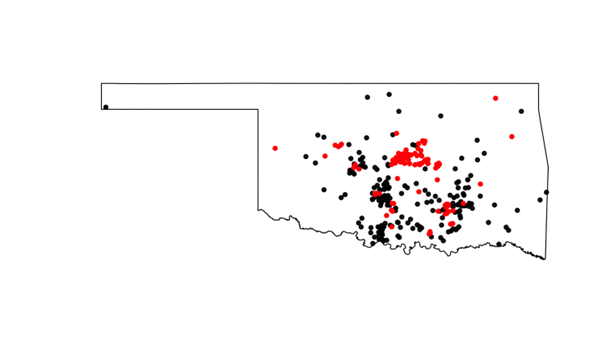
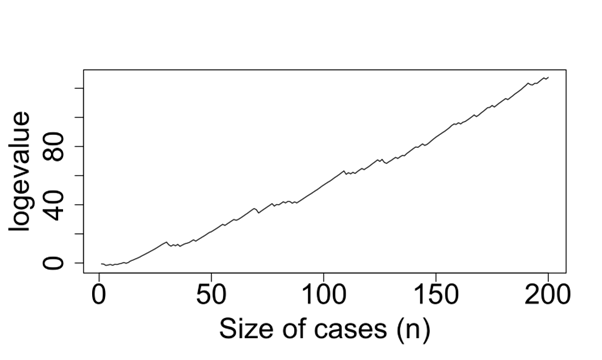
We highlight one such predictive scheme here, the so-called Predictive Recursion (PR) algorithm that is a fast, recursive and nonparametric algorithm that estimates the underlying mixing distribution of a general mixture distribution. This is important here on two accounts. First, since the algorithm fits a general mixture density, e.g., a location–scale mixture of Gaussian distributions, it is sufficiently flexible to capture a wide collection of true distributions. Second, PR is a recursive algorithm which means that it efficiently learns the mixing distribution and hence updates the mixture density estimate and corresponding likelihood as new data arrive. With these two crucial points, we construct a PR-based e-process called a PRe-process for testing a composite null family of probability distributions versus a composite alternative family. This uses the PR-based marginal likelihood in the numerator of the e-process and a supremum under the null in the denominator. This construction satisfies the anytime-valid properties of e-processes and the value of the PRe-process grows optimally if the null is indeed not true as the sample size approaches infinity; see [3]. For a practical illustration, we consider the earthquake locations in the state of Oklahoma from 2000–2011 and model them as a spatial Poisson point process. There is suspicion of fracking activities in this region since 2009 and we investigate this by testing for whether the post-fracking intensity function is proportional to the pre-fracking intensity function via the PRe-process. Figure 1 shows that the log PRe-process shows an increasing trend: so, there is an accumulation of evidence against the null hypothesis and hence a significant effect of fracking.
Beyond their use in the construction of e-processes as outlined above, predictive schemes apparently have a fundamental role to play in the broader context of uncertainty quantification. The specific question we have in mind here, going back at least to Keynes and Carnap, is if one can define an “objective” empirical probability associated with an observed data sequence. Building on the classic work of von Mises, Phil Dawid set out to define a notion of objective probability through what he called calibrated forecasting systems – PR defines a calibrated forecasting system under relatively mild conditions. An interesting conclusion Dawid drew from the famous Blackwell-Dubins theorem is that, while calibrated forecasting systems are incredibly diverse, the actual probabilities they assign to the observed data sequence must agree asymptotically; hence one can define a genuinely “objective” empirical probability as the common forecast value assigned by all calibrated forecasting systems asymptotically. The efforts by Vladimir Vovk and others to generalize Dawid’s results to finite sequences, etc., were surely influential to the development of Shafer and Vovk’s game-theoretic probability, which, coming full circle, provides a deeper foundation for the latest e-process advancements. This forecasting system perspective and “objective probability” insight opens new opportunities for PR as a genuine “model” for observations, meaningful and flexible, rather than as a method for estimating unknown mixing distributions. Suffice it to say, PR and the corresponding PRe-process have yet to realize their full potential.
Links:
[L1] https://www.usgs.gov/news/national-news-release/century-induced-earthquakes-oklahoma
[L2] https://www.ou.edu/ogs/research/earthquakes/catalogs
References:
[1] P. Grünwald, R. de Heide, and W. M. Koolen, “Safe testing,” Journal of the Royal Statistical Society: Series B, 2024.
[2] J. Larsson, A. Ramdas, and J. Ruf, “The numeraire e-variable and reverse information projection,” The Annals of Statistics, 2025.
[3] V. Dixit and R. Martin, “Anytime valid and asymptotically optimal inference driven by predictive recursion,” Biometrika, 2025.
Please contact:
Vaidehi Dixit
University of Nottingham, United Kingdom

