









by Kostas Stefanidis and Kjetil Nørvåg
gRecs is a research prototype system designed for providing suggestions to groups of users about items of potential interest. In particular, gRecs proposes an extensive model for group recommendations based on recommendations for items liked by similar users to the group members. This is achieved with the use of data mining techniques. More specifically, since the main bottleneck is to identify the most similar users to a given one, we model the user-item interactions in terms of clustering and use the extracted clusters for predictions.
Recommendation systems provide suggestions to users about a variety of items, such as movies and restaurants. The large majority of these systems are designed to make recommendations for individual users. However, there are contexts in which the items to be suggested are intended for a group of people, rather than an individual; for instance, recommendations for restaurants, tourist attractions, movies, TV programs and holiday destinations. Recent approaches try to satisfy the preferences of all group members either by creating a joint profile for the group and suggesting items with respect to this profile or by aggregating the single user recommendations into group recommendations. gRecs opts for the second approach owing to its greater flexibility and potential for efficiency improvements.
gRecs proposes a framework for group recommendations following the collaborative filtering approach. The most prominent items for each user of the group are identified based on items that similar users liked in the past. Users are considered similar if there is an overlap in the items consumed. In particular, the two types of entity that are dealt with in recommendation systems, ie, users and items, are represented as sets of ratings, preferences or features. Users initially rate a (typically small) subset of items and ratings are expressed in the form of preference scores. A recommendation engine estimates preference scores for the unrated items and offers appropriate recommendations. Once the unknown scores are computed, the k items with the highest scores are recommended to users.
To efficiently aggregate the single user recommendations into group recommendations, we leverage the power of a top-k algorithm. We employ three different aggregation designs: (i) the least misery design, capturing cases where strong user preferences act as a veto, (ii) the most optimistic design, capturing cases where the most satisfied member is the most influential one, and (iii) the fair design, capturing more democratic cases. To deal with reliability issues, we introduce the notion of support in recommendations to model how confident the recommendation of an item for a user is. Group recommendations are presented to users along with explanations about the reasons that the particular items are being suggested. Explanations are given as text using a template mechanism.
A main problem of this approach is to identify the most similar users for each user in the group. A solution that involves no pre-computation requires computing the similarity measures between each user in the group and each user in the database. To avoid exhaustively searching for similar users, we perform some pre-processing steps offline. In particular, we propose building clusters of similar users, considering as similar those users that have similar preferences. To partition users into clusters we employ a bottom-up hierarchical agglomerative clustering algorithm. Initially, our algorithm places each user in a cluster of his own. Then, at each step, it merges the two most similar clusters. The similarity between two clusters is defined as the minimum similarity between any two users that belong to these clusters (max linkage). The algorithm terminates when the similarity of the closest pair of clusters violates a user similarity threshold δ. Ideally, the most similar users to a specific user are the members of the cluster that the user belongs to. Recommendations are computed based on the preferences of these cluster members. Figure 1 shows a high level representation of the architecture of our system.
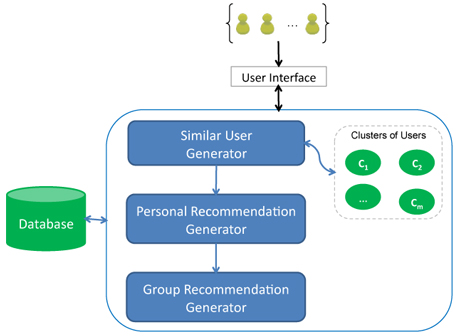
Figure 1: gRecs architecture overview
Our results show that employing user clustering considerably improves the execution time, while preserving a satisfactory quality of recommendations [1]. To deal with the high dimensionality and sparsity of ratings, we envision subspace clustering to find clusters of similar users and subsets of items for which these users have similar ratings.
We designed and developed the gRecs system at the Norwegian University of Science and Technology in Trondheim, Norway, funded by the ERCIM “Alain Bensoussan” Fellowship Programme, in collaboration with Irini Ntoutsi and Hans-Peter Kriegel from the Ludwig Maximilian University of Munich, Germany.
Reference:
[1] I. Ntoutsi, K. Stefanidis, K. Nørvåg and H-P. Kriegel: “Fast Group Recommendations by Applying User Clustering”, in proc. of ER 2012.
Please contact:
Kostas Stefanidis, Kjetil Nørvåg, NTNU, Norway
E-mail:

