









by Ross King, Rainer Schmidt, Christoph Becker and Sven Schlarb
The digital collections of scientific and memory institutions – many of which are already in the petabyte range – are growing larger every day. The fact that the volume of archived digital content worldwide is increasing geometrically, demands that their associated preservation activities become more scalable. The economics of long-term storage and access demand that they become more automated. The present state of the art fails to address the need for scalable automated solutions for tasks like the characterization or migration of very large volumes of digital content. Standard tools break down when faced with very large or complex digital objects; standard workflows break down when faced with a very large number of objects or heterogeneous collections. In short, digital preservation is becoming an application area of big data, and big data is itself revealing a number of significant preservation challenges.
The EU FP7 ICT Project SCAPE (Scalable Preservation Environments), running since February 2011, was initiated in order to address these challenges through intensive computation combined with scalable monitoring and control. In particular, data analysis and scientific workflow management play an important role. Technical development is carried out in three sub-projects and will be validated in three Testbeds (refer to Figure 1).
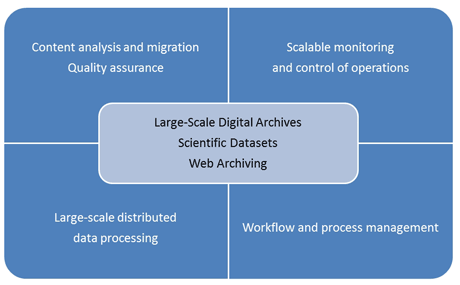
Figure 1: Challenges of the SCAPE project
Testbeds
The SCAPE Testbeds will examine very large collections from three different application areas: Digital Repositories from the library community (including nearly two petabytes of broadcast audio and video archives from the State Library of Denmark, who are adding more than 100 terabytes every year), Web Content from the web archiving community (including over a petabyte of web harvest data), and Research Data Sets from the scientific community (including millions of objects from the UK Science and Technology Facilities Council’s Diamond Synchrotron source and ISIS suite of neutron and muon instruments). The Testbeds provide a description of preservation issues with a special focus on data sets that imply a real challenge for scalable solutions. They range from single activities (like data format migration, analysis and identification), to complex quality assurance workflows. These are supported at scale by solutions like the SCAPE Platform or Planning and Monitoring services detailed below. SCAPE solutions will be evaluated against defined institutional data sets in order to validate their applicability in real life application scenarios, such as large scale data ingest, analysis, and maintenance.
Data Analysis and Preservation Platform
The SCAPE Platform will provide an extensible infrastructure for the execution of digital preservation workflows on large volumes of data. It is designed as an integrated system for content holders employing a scalable architecture to execute preservation processes on archived content. The system is based on distributed and data-centric systems like Hadoop and HDFS and programming models like MapReduce. A suitable storage abstraction will provide integration with content repositories at the storage level for fast data exchange between the repository and the execution system. Many SCAPE collections consist of large binary objects that must be pre-processed before they can be expressed using a structured data model. The Platform will therefore implement a storage hierarchy for processing, analysing and archiving content, relying on a combination of distributed database and file system storage. Moreover, the Platform is in charge of on-demand shipping and deploying the required preservation tools on the cluster nodes that hold the data. This is being facilitated by employing a software packaging model and a corresponding repository. The SCAPE vision is that preservation workflows, based on assembling components using the Taverna graphical workbench, may be created on desktop computers by end-users (such as data curators). The Platform’s execution system will support the transformation of these workflows into programs that can be executed on a distributed data processing environment.
Scalable Planning and Monitoring
Through its data-centric execution platform, SCAPE will substantially improve scalability for handling massive amounts of data and for ensuring quality assurance without human intervention. But fundamentally, for a system to be truly operational on a large scale, all components involved need to scale up. Only scalable monitoring and decision making enables automated, large-scale systems operation by scaling up the control structures, policies, and processes for monitoring and action. SCAPE will thus address the bottleneck of decision processes and information processing required for decision making. Based on well-established principles and methods, the project will automate now-manual aspects such as constraints modelling, requirements reuse, measurements, and continuous monitoring by integrating existing and evolving information sources and measurements.
Conclusions
At the end of the first project year, the SCAPE project can already offer real solutions to some of the big data challenges outlined above, in the form of a scalable platform design and infrastructure, initial tools and workflows for large-scale content analysis and quality assurance, and an architecture for scalable monitoring and control of large preservation operations. Initial results in the form of deliverables, reports and software are publicly available on the project website, wiki, and Github repository. We are confident that the project will have significant impact over the remaining two and one-half years.
This work was partially supported by the SCAPE Project. The SCAPE project is co-funded by the European Union under FP7 ICT-2009.4.1 (Grant Agreement number 270137).
Links:
http://www.scape-project.eu/
http://wiki.opf-labs.org/display/SP/Home
https://github.com/openplanets/scape
Please contact:
Ross King
AIT Austrian Institute of Technology GmbH
Tel: +43 (0) 50550 4271
E-mail:
