









by Javier D. Fernández, Miguel A. Martínez-Prieto and Mario Arias
The potential of Semantic Big Data is currently severely underexploited due to their huge space requirements, the powerful resources required to process them and their lengthy consumption time. We work on novel compression techniques for scalable storage, exchange, indexing and query answering of such emerging data.
The Web of Data materializes the basic principles of the Semantic Web. It is a collective effort for the integration and combination of data from diverse sources, allowing automatic machine-processing and reuse of information. Data providers make use of a common language to describe and share their semi-structured data, hence one person, or a machine, can move through different datasets with information about the same resource. This common language is the Resource Description Framework (RDF), and Linked Open Data is the project that encourages the open publication of interconnected datasets in this format.
Meanwhile, the world has entered a data deluge era in which thousands of exabytes (billion gigabytes) are created each year. Human genome data, accurate astronomical information, stock exchanges worldwide, particle accelerator results, logs of Internet use patterns and social network data are just a few examples of the vast diversity of data to be managed. This variety, together with the volume and the required velocity in data processing, characterize the “big data” and its inherent scalability problems. With the current data deluge transforming businesses, science and human relationships, to succeed in Semantic Big Data management means to convert existing scattered data into profitable knowledge.
A new paradigm for such large scale management is emerging, and new techniques to store, share, query, and analyze these big datasets are required. Our research is focused on scalable RDF management within a typical Create-Publish-Exchange-Consume scenario, as shown in Figure 1. To date, big RDF datasets are created and serialized, in practice, using traditional verbose syntaxes, still conceived under a document-centric perspective of the Web. Efficient interchange of RDF is limited, at best, to compress these plain formats using universal compression algorithms. The resultant file lacks logical structure and there is no agreed way to efficiently publish such data, ie to make them (publicly) available for diverse purposes and users. In addition, the data are hardly usable at consumption; the consumer has to decompress the file and, then, to use an appropriate external management tool. Similar problems arise when managing RDF in mobile devices; although the amount of information could be potentially small, these devices have even more restrictive requirements, not only for transmission costs/latency, but also for post-processing due to their inherent memory and CPU constraints.
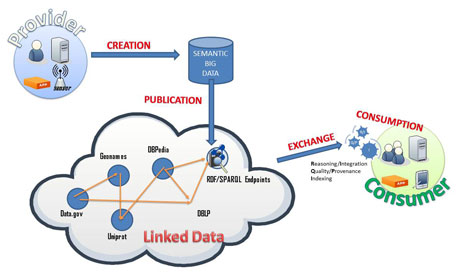
Figure 1: Create-Publish-Exchange-Consume scenario in the Web of Data
We address the scalability drawbacks depicted in the previous workflow by proposing novel compressed structures optimized for the storage, exchange, indexing and querying of big RDF. We firstly design an efficient (binary) RDF serialization format, called HDT (Header-Dictionary-Triples). In this proposal, we called for the need to move forward RDF syntaxes to a data-centric view. HDT modularizes the data and uses the skewed structure of big RDF graphs to achieve large spatial savings. In addition, it includes metadata describing the RDF dataset which serves as an entrance point to the information on the dataset and leads to clean, easy-to-share publications. Our experiments show that big RDF is now exchanged and processed 10-15 times faster than traditional solutions, being rapidly available for final consumption.
RDF datasets are typically consumed through a specific query language, called SPARQL. Several RDF stores provide SPARQL resolution both for local consumption or facilitating an online query service for third parties through SPARQL Endpoints. We have developed a lightweight post-processing which enhances the exchanged HDT with additional structures to provide full SPARQL resolution in compressed space. Furthermore, we were one of the first groups to empirically analyse SPARQL usage logs. These results provide valuable feedback to our work as well as other RDF store designers, especially in the tasks of query evaluation and index construction.
The HDT format has recently been accepted as a W3C Member Submission, highlighting the relevancy of ‘efficient interchange of RDF graphs’. We are currently working on our HDT-based store. In this sense, compression is not only useful for exchanging big data, but also for distribution purposes, as it allows bigger amounts of data to be managed using fewer computational resources. Another research area where we plan to apply these concepts is on sensor networks, where data throughput plays a major role. In a near future, where RDF exchange together with SPARQL query resolution will be the most common daily task of Web machine agents, our efforts will serve to alleviate current scalability drawbacks.
Links:
DataWeb Research Group: http://dataweb.infor.uva.es
RDF/HDT: http://www.rdfhdt.org
HDT W3C Member Submission: http://www.w3.org/Submission/2011/03/
Please contact:
Javier D. Fernández
University of Valladolid, Spain
E-mail:
Miguel A. Martínez-Prieto
University of Valladolid, Spain
E-mail:
Mario Arias
DERI, National University of Ireland Galway, Ireland
E-mail:
