








by Per Brand
Vision Cloud is an ongoing European project on cloud computing. The novel storage and computational infrastructure is designed to meet the challenge of providing for tomorrow’s data-intensive services.
The two most important trends in information technology today are the increasing proliferation of data-intensive services and the digital convergence of telecommunications, media and ICT. A growing number of services aggregate, analyze and stream rich data to service consumers over the Internet. We see the inevitability of media, telecommunications and ICT services becoming merged into one operating platform, where content and ICT resources (including storage, network, and computing) are integrated to provide value-added services to users. The growing number, scale, variety and sophistication of data-intensive services impose demanding requirements that cannot be met using today’s computing technologies. There is the need to simultaneously service millions of users, accommodate the rapid growth of services and the sheer volume of data, while at the same time providing high availability, low maintenance costs and efficient resource utilization.
The two critical ingredients to deliver converged data-intensive services are the storage infrastructure and the computational infrastructure. Not only must the storage offer unprecedented scalability, good and tunable availability, it must also provide the means to structure, categorize, and search massive data sets. The computational framework needs to provide user-friendly programming models capable of analyzing and manipulating large data sets in a resource-aware and efficient manner.
The ongoing European IP project Vision Cloud (October 2010-September 2013) addresses these issues and is developing a distributed and federated cloud architecture as well as a reference implementation. Use cases are taken from the domains of telecommunication (with Telenor, France Telecom, and Telefonica as partners), media (with Deutsche Welle, and RAI), health (Siemens) and enterprise (SAP). In addition to SICS, other partners include IBM, Engineering, National Technical University of Athens, Umeå University, the University of Messina and SNIA.
An important principle of the Vision Cloud architecture is that storage and computation are tightly coordinated and designed to work together. Indeed, one could say there is no clear dividing line between the two. We will illustrate with two examples taken from Vision Cloud use cases, but first we briefly describe the storage service and computational model.
The storage service encapsulates objects together with their metadata. Metadata is used by many different actors at various levels, ranging from end-user metadata, organizational metadata, metadata belonging to PaaS services, to system metadata. The metadata of a data object characterizes the object from different points of view. For example, one metadata field might specify that a document is ‘type: text’ and ‘subject: computer_science’, while another (system) field gives the creation time of the object. The storage service also offers search facilities whereby objects with given metadata tags and values may be found.
In Vision Cloud the units of computation are called storlets. Storlets may be seen as a computation agent that lives, works and eventually dies in the cloud. The storlet is an encapsulated computation where all interaction with other cloud services is given in the storlet parameters. The storlet programming model specifies the format for these storlet parameters. Parameters include credentials, the identity of objects it will access, constraints it must obey during operation, and most importantly, its triggers; the conditions that will cause the storlet to become active and actually perform some computation. The objects that the storlet will work on are either provided by the data object parameters or given by the triggering event that activates the storlet. An important aspect of the runtime system is that storlets execute close to the data they access. Some examples follow.
In a perfect world a user, organization might define an appropriate metadata scheme for object classification; each and every user will appropriately tag each and every object they inject into the cloud. However, experience tells us that this is not the case, users forget and make mistakes. Hence it is useful to have analysis programs that automatically annotate and check objects as they are injected.
Another example addresses the proliferation of different media formats. One possibility is that upon ingestion data is automatically converted by appropriate storlets to all the formats that might be needed upon access for all devices. Another possibility is to, transparent to the user, perform on-the-fly transcoding from a given standard format to one suitable for the particular accessing device being used. Note that if one data item can be transcoded from another, the best choice depends on the relative costs of computation and storage. With storlets this choice can be done automatically, transparently, and even dynamically.
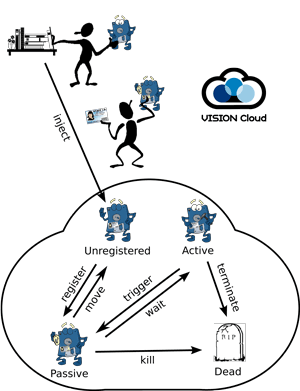
Figure 1: Example of computational storage Vision Cloud.
In Figure 1 a user copies a storlet from a storlet library, which could also be in the cloud. The user provides the storlet with the necessary additional parameters, which would typically include user credentials – as the storlet is acting as an extension of the user with the same rights and privileges. The storlet is injected into Vision Cloud. The system places the storlet appropriately (eg close to the data it will need to access (if known). The system will also extract the trigger conditions from the storlet, and register the storlet so when and if the appropriate trigger event occurs this information is propagated. The storlet becomes active and performs some computation, possibly modifying data objects or their metadata. When the computation has finished the storlet generally returns to the passive state waiting for a new trigger event.
Link: http://www.visioncloud.eu
Please contact:
Per Brand
SICS, Sweden
E-mail: