









by Peter Zinterhof
In a joint project, scientists at University Salzburg and SALK (Salzburger Landeskrankenanstalten) explore how to apply machine-learning techniques to assess the huge amount of image data generated by computed tomography.
Modern radiology offers a wide range of imaging tools for diagnosis and for planning of treatments of various severe illnesses. As techniques such as MRI and CT (computed tomography) are employed on a large scale, clinicians all over the world are confronted with an increasing amount of imaging data. These data have to be analysed and assessed by trained radiologists in a mostly manual process, which requires high levels of concentration for long periods of time. Also, the intrinsic power of modern medical imaging technology opens up the possibility of detecting conditions in a patient that weren’t even on the scope of the physician who initiated the diagnostic run in the first place. As a consequence, in addition to concentrating on the initial diagnostic directions, the assessing radiologist is also responsible for detecting and correctly reporting other medical issues revealed by a patient’s data. As a result, the overall diagnostic process is very demanding and sometimes even error-prone.
In a joint research project with the department for radiology at SALK (Salzburger Landeskrankenanstalten), we aim to explore the application of certain machine-learning techniques for image segmentation in the field of computed tomography. One such approach is based on principle component analysis (PCA), also known as Karhunen-Loeve transform. This method derives statistically uncorrelated components of some given input data set, allowing robust recognition of patterns in new datasets. Our algorithm works on image patches of 64 x 64 pixels, allowing us to detect image details up to this size within a single CT frame.
During an initial setup phase we semi-automatically generate and label a large number – usually millions – of patches that stem from a training sample of some 500 patients’ data.(50 GB DICOM)
An auto-correlation matrix of the pixel intensities of the patches is made up and in a second step both the Eigenvalues and Eigenvectors of that matrix are computed and the Eigenvectors corresponding to the 32 largest Eigenvalues are retained for further processing. Based on these Eigenvectors we are able to build a codebook that holds the necessary information for recognizing medically relevant features later on.
Such codebooks are composed of millions of short vectors of length 32 (also being called feature vectors), which are assigned specific class labels, eg ‘kidney’, ‘tissue’, ‘bone’. New data (ie image patches) will then also be decomposed into feature vectors by means of the very same Eigenvectors. At the core of the recognition algorithm we take a previously unknown feature vector, ‘look up’ its corresponding entry in the codebook, and assign that vector the same class label as the entry found in the codebook. The look-up process is based on finding the entry with minimal Euclidean distance to the unknown vector.
As we deal with a high-dimensional vector space model, the lookup process itself is not suitable for typical optimizations, such as kD-trees or clustering. This is a direct consequence of the ‘curse of dimensionality’, which basically limits us to a standard linear search operation within the codebook as the space- and execution-time optimal approach to solve the retrieval problem.
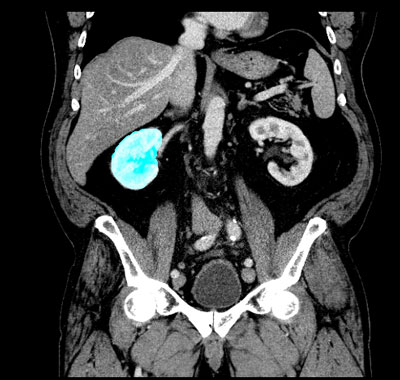
Figure 1: Raw segmentation of the right kidney
For a new patient, the whole set of CT data is then checked frame by frame at the ‘regions of interest’, which consist of some 64 000 pixels per frame (see picture 1 with marked area of the left kidney). On average 2 PB (2 million GB) of data have to be processed per patient. Fortunately, this computationally complex process lends itself very well to distributed parallel hardware, eg clusters of general purpose graphics units (GPU) that are especially powerful in the field of high-throughput computing.
In our cluster setup of 16 distributed NVIDIA GPUs (Fermi and GT200 class) we achieve high recognition rates for the complete segmentation of the kidney area in a patient’s CT data in a time frame of 10-12 minutes (wall-time), based on 10 million codebook entries. One of the charms of PCA is its relative resilience against over-fitting of the model data, so increasing the amount of training data in general will not reduce its generalization capability (as can be the case in artificial neural networks). Hence, the approach is easily extendible both in terms of additional compute nodes and additional training data, which will help us to sift relevant information from this vast data space even faster and at higher quality.
Our developments aid both clinicians as well as patients by enabling automatic assessment of large amounts of visual data on massively parallel computing machinery.
Please contact:
Peter Zinterhof, Universität Salzburg, Austria
Tel: +43 662 8044 6771
E-mail:
