









by Vladimir Ivanov
This project has led to the publication of metadata(as Linked Data) relating to more than 40 000 photos from Russia’s oldest museum.
In 2009 general activity on digitization carried out by Peter the Great Museum of Anthropology and Ethnography Russian Academy of Sciences (the Kunstkammer or MAE RAS) had led to the creation of dataset consisting of more than 40 000 digital images and their descriptions in English and Russian. The dataset supplied with a search tool is accessible on the MAE RAS's website in HTML format. In 2010 the Computational Linguistics Laboratory of the Kazan Federal University initiated the Open Kunstkammer Data project (OKD) aimed at standardization of metadata representation and publication the dataset as Linked Data.
The OKD is a research and development project inspired by Tatyana Bogomazova, head of IT department of MAE RAS. Bogomazova articulated the project's aim, which is to enrich the existing dataset using the International Committee for Documentation of the International Council of Museums (ICOM/CIDOC) recommendations and the best practices of the Semantic Web. To this end, two steps were taken. First, a legacy database schema was mapped to the Web Ontology Language (OWL) representation of the CIDOC Conceptual Reference Model (CIDOC CRM). The mapping process raised a few semantic issues which were resolved only after consultations with museum staff and IT-experts. The mapping was defined in a machine readable format which allows automatic generation of target (CIDOC CRM) representation for each source metadata record. The result of this step is an Resource Description Framework (RDF) dataset that contains the CIDOC CRM classes, properties and their interrelated instances. The dataset describes the meaning of the source data in terms of the CIDOC CRM.
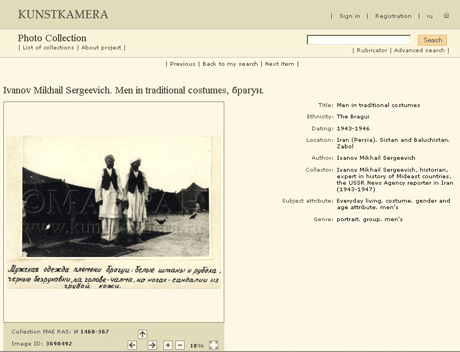
Figure 1: The website of MAE RAS.
An additional task carried out in the OKD project was to “SKOSify” MAE RAS’s controlled bilingual vocabularies (“SKOS” stands for Simple Knowledge Organization System). The list of vocabularies includes “Places”, “Actors (Authors and Collectors)”, “Expeditions”, “Ethnicity”, “Subjects” and “Genres”. SKOS-based versions of these vocabularies are also represented in RDF format. The total amount of RDF-triples (ie statements in the form of “subject-predicate-object”) in the RDF-dataset is more than 5 million (for both languages). A special software component supporting regular updating of the RDF-dataset was also developed. Its implementation was quite straightforward because updates made by users never affect the source database schema. There is therefore, no need to update the mapping. Finally, all the RDF-triples were loaded into the Virtuoso Universal Server RDF-store. Public SPARQL Protocol and RDF Query Language endpoint (http://data.kunstkamera.ru/sparql) is supported by Open Source edition of the Virtuoso Universal Server. The server's software also supports dereferencing of URIs, which means that any URI in the RDF-store not only identifies a resource (eg image or vocabulary concept), but also provides access to corresponding RDF-triples which describe the resource.

Figure 2: A graphical representation of the mapping fragment.
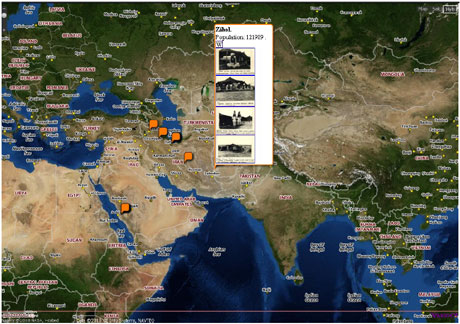
Figure 3: A map with creation places and museum items.
The second step is the definition of mappings between concepts from MAE RAS controlled vocabularies and concepts from external datasets. DBPedia (http://dbpedia.org) and Geonames (http://geonames.org) were chosen as target datasets for their multilingualism and global coverage. The main issue we faced here was ambiguity. For example, concepts from the “Places” vocabulary can have up to hundreds of “equivalents” when matched to the Geonames concepts using labels. A set of special heuristic disambiguation procedures were developed. For both target datasets these procedures significantly decreased the ambiguity. More than 60% of matched concepts (in the “Place” vocabulary) have a single equivalent and only 6% of matched concepts have more than ten equivalents after applying the procedure. However, manual disambiguation is still required.
External datasets enrich the source database with useful information. Geographic coordinates from Geonames could be useful when showing the MAE RAS dataset on the global map (see Figure 3). Multiple languages of DBPedia resources allow multilingual searching.
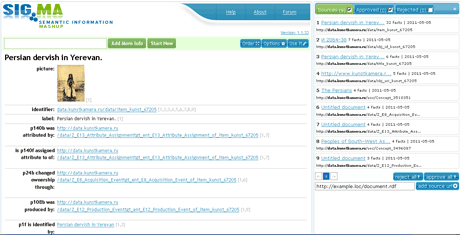
Figure 4: MAE RAS description used by the Sig.ma.
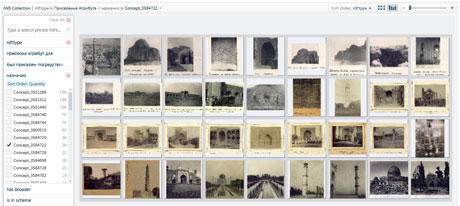
Figure 5: A set of photos to which two attributes ("Islam" and "Cultural landscape") have been assigned.
The MAE RAS RDF-dataset could be useful in external services and semantic web applications. For instance, triples from the dataset are already used by the Sig.ma (http://sig.ma) semantic mashup application (see Figure 4).
Other applications can also consume the MAE RAS RDF-triples online. A screenshot of such a software component based on Information Workbench framework (http://iwb.fluidops.com/) is shown in Figure 5.
Future research and development activities are related to improvement of automatic matching and disambiguation quality, integration with the original search tool and web application deployed on the www.kunstkamera.ru, and providing end-users with new services based on the published dataset.
Links:
http:// www.kunstkamera.ru
http://data.kunstkamera.ru/sparql
Please contact:
Vladimir Ivanov
Kazan Federal University, Computational Linguistics Laboratory, Kazan, Russia
E-mail:
