









by Elena Console, Anna Tonazzini and Fabio Bruno
Extracting and archiving information from digital images of documents is one of the goals of the project AMMIRA (multispectral acquisition, enhancing, indexing and retrieval of artifacts), led by Tea-Sas, a service firm based in Catanzaro, Italy, with the collaboration of two Italian research teams, the Institute of Information Science and Technologies of CNR in Pisa, and the Department of Mechanical Engineering of the University of Calabria in Cosenza. AMMIRA is supported by European funding, through the Italian regional program for integrated support to enterprises.
Gathering as much information as possible from the documents of our past is essential to preserve our cultural heritage for future generations, especially in an era when the documents are migrating from traditional supports towards the new electronic devices. For many historical documents, this involves capturing their appearance, as well as mitigating distortions and degradations, in order to help human or automatic readers to extract their content. All the information extracted must then be organized to facilitate storage, access and retrieval.

Figure 1: Capturing pages from an ancient book: the AMMIRA DTA Chroma multispectral camera.
Depending on the type of document, the first step is to choose the most accurate and detailed data capture modalities. These modalities include the acquisition geometry and the spatial and spectral ranges and resolutions. The imaging system that we have adopted consists of a high-resolution, multispectral, computer-controlled camera with three visible and two infrared channels, coupled with a visible-ultraviolet lighting system and a structured-light projector for 3D acquisition. Thus, depending on the importance and the state of preservation of a document, we can represent it through panchromatic or colour images in the visible range, infrared reflectance or transmission images, and ultraviolet fluorescence images and, in some cases, a precise 3D shape. This flexibility of representation can help us detect and isolate many kinds of hidden features, and also account for geometrical distortions caused by deformations of the document support. The 3D acquisition augments the level of information that we are able to preserve, because deformations and degradations often describe the history of a manuscript. So, the fruition of the digital replica of a manuscript or an entire book acquires a new dimension as these can be represented as a 3D object in the space.
However, all these features are still raw data, ie a more or less detailed representation of the document appearance with no semantics relating to it. The images must next be freed from interferences and distortions, extracting all the features to which, at some level, semantics can be attached (eg “main text”, “footnotes”, “images-graphics”, etc.). The software system that supports our imaging system is capable of performing many of these tasks. First, we can spatially co-register the available images, after correcting 2D or 3D geometric distortions if necessary. This provides us with a set of data maps with precisely located pixels. Further processing includes virtual restoration, ie removal of distortions and interference (stains, blur, bleed-through), and extraction of features and patterns. The latter task is accomplished through several fully or partially automatic approaches, based mainly on linear data models.
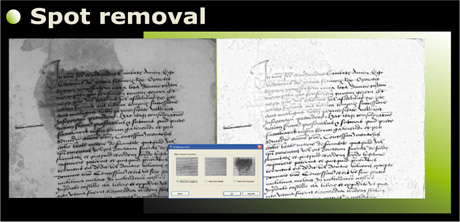
Figure 2: A screenshot from the AMMIRA image manipulation user interface.
The key to incorporating semantics into the processed data is to adopt an efficient metadata schema that traces all the processing steps applied to any piece of data and all its relationships to other stored material, including all the administrative and descriptive information needed and, eventually, enabling content-based retrieval from a large data repository. The parts classified as text can be translated into machine-readable form through automatic or semi-automatic character recognition systems.
The AMMIRA project began in September 2009 and will be completed in September 2011. The partners all have a consolidated experience in this field. The research is expected to continue in the future with the aim of implementing a fully integrated hardware-software system.
Link:
AMMIRA homepage: http://www.ammira.eu
Please contact:
Elena Console
TEA-SAS, Italy
E-mail :
Anna Tonazzini
ISTI-CNR, Italy
E-mail :
Fabio Bruno
University of Calabria, Italy
E-mail:
