









Large-scale computing platforms will soon become a pervasive technology available to companies of all sizes. They will serve thousands, or even millions of users through the Internet. However, existing technologies are based on a hierarchically managed approach that does not possess the required scaling properties. Moreover, existing systems are not equipped to handle the dynamism caused by severe failures or load surges. We conjecture that using self-organizing techniques for system (re)configuration can improve both the scalability properties of such systems as well as their ability to tolerate variations in load and increased failure rates. Specifically, we focus on the deployment of virtual machine images onto physical machines that reside in different parts of the network. Our objective is to construct balanced and dependable deployment configurations that are resilient and support elasticity. To accomplish this, a method based on a variant of Ant Colony Optimization is used to find efficient deployment mappings for a large number of replicated virtual machine images that are deployed concurrently. The method is completely decentralized; ants communicate indirectly through pheromone tables located in the nodes.
Central to our work – conducted at the Department of Telematics at NTNU – are distributed software services hosted in hybrid cloud-like environments possibly with multiple providers and their non-functional requirements, for such as those related to system performance and dependability. We find optimal deployment mappings involving multiple services, ie map service components – VMs in an IaaS scenario – in the software architecture to the underlying platforms for best possible execution. Requirements are used to construct appropriate cost functions that guide our heuristic optimization method. In particular, we obtain a decentralized method using swarm intelligence, free of discrepancies of centralized solutions, such as single point of failures and performance bottlenecks.
Nodes hosting a service may be heterogeneous and may provide a dynamic environment. For example, nodes can join and leave the network in an unpredictable manner, in particular, in large-scale data-centers designed to handle failures, which are present most of the time. Changing context of distributed services requires the capability of adaptation to satisfy QoS-requirements, while taking into account costs from the service providers’ perspective. The wide range of possible requirements makes the deployment problem a multi-faceted challenge demanding multi-dimensional optimization (see. Figure 1).
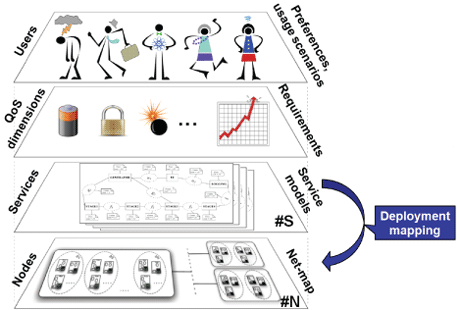
Figure 1: The deployment problem.
Making Placement Decisions in a Cloud Computing Setting
We consider a large-scale data-center consisting of a collection of nodes (see. Figure 2), which can be organized into sets of clusters. The data-center hosts a set of services (S1, S2, … in Figure 2 (a)), in which each component (V11, V12, …) may be replicated (R111, R121, …) for fault tolerance and/or load-balancing purposes. The method is implemented in the form of ant-like agents moving in the network to identify potential locations for placement (represented by the green and blue ants in Figure 2 (b)). Different ant species are responsible for different services. The execution environment has to install, run and migrate VMs. Our method, however, is transparent regarding the execution framework. Nodes have pheromone tables manipulated by visiting ants to reflect their knowledge of possible mappings. These tables are used by ants to select suitable deployment mappings. To find mappings satisfying the requirements, the Cross-Entropy Ant System (presented in ERCIM News No. 64) is used, which works by evaluating the findings using a cost function. CEAS then uses the Cross-Entropy stochastic optimization method to gradually alter the pheromones according to the cost of the mapping found. To deploy a service, at least one node must be running a nest for that service. Tasks of a nest are: (i) to emit ants for the associated service, and (ii) trigger placement, once a convergence criteria is satisfied.
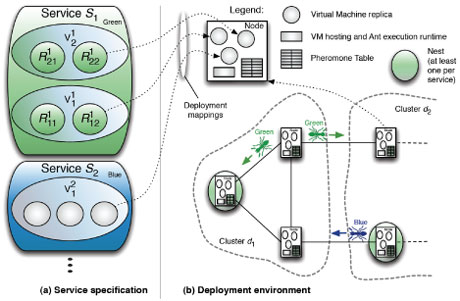
Figure 2: CE Ant System for Deployment Mapping.
To demonstrate feasibility of our approach, we have modelled several scenarios and conducted simulations, including tailored examples of traditional NP-hard task assignment problems, deployment problems of collaborating software components within multiple parallel services and deployment of VMs in virtualized computing clouds. In the test scenarios we have looked at the convergence properties of our algorithm, different possible encodings of pheromone values, and obtained mappings that with high confidence satisfy the requirements of the services provisioned, such as dependability (cluster-disjointness and co-location avoidance) and load-balancing among the nodes. Cross-validation of the results obtained using our distributed logic against centralized solutions for finding mappings has been conducted applying integer linear programming further increasing confidence in our approach.
Discussion
We are developing a distributed optimization algorithm based on an ant colony system, the CEAS. It finds efficient mappings between service components, such as VMs in a cloud computing setting and hosts suitable for execution. Identified mappings adhere to predefined non-functional requirements specified in formal models. The algorithm is at present implemented in a discrete event simulator environment and we are currently working on porting it to a Java based environment, which would, in the long term, ease experimentation in an online network. Future plans include extending our method with energy-saving aspects that have become key in production data-centers, and further improving scalability and adaptation capabilities of our algorithm.
Links:
http://www.item.ntnu.no/~csorba/
http://www.item.ntnu.no/~poulh/
Please contact:
Máté J. Csorba or Poul E. Heegaard,
Dept. of Telematics, NTNU, Norway
Tel: +47 73590786
E-mail: {csorba, poulh}@item.ntnu.no
