









Virtualization technologies have been a key element in the adoption of Infrastructure-as-a-Service (IaaS) cloud computing platforms as they radically changed the way in which distributed architectures are exploited. However, a closer look suggests that the way of managing virtual and physical resources still remains relatively static.
Through an encapsulation of software layers into a new abstraction - the virtual machine (VM) - cloud computing users can run their own execution environment without considering, in most cases, software and hardware restrictions as it was formerly imposed by computing centers. By using specific APIs, users can create, configure and upload their VM to IaaS providers, which in turn are in charge of deploying and running the requested VMs on their physical architecture.
Due to the growing popularity of these IaaS platforms, the number of VMs and consequently the amount of data to manage is increasing. Consequently, IaaS providers have to permanently invest in new physical resources to extend their infrastructure. This leads to concerns, which are being addressed by the Cluster and Grid Communities, about the management of large-scale distributed resources.
Similarly to previous works that led to the Grid paradigm, several works propose the interconnection of distinct IaaS platforms to produce a larger infrastructure. In cloud computing terminology, we refer to such a federation as a sky computing platform. Although it improves flexibility in terms of VM management by delivering, for instance, additional resources to users when one site is overloaded or by offering more efficient nodes when relevant, most of the available IaaS solutions assign the VMs to the physical machines in a static manner and without reconsidering the allocation throughout the whole infrastructure during their execution.
Such an allocation strategy is not appropriated to tackle volatility constraints intrinsic to large-scale architectures (node additions/removals, node/network failures, energy constraints etc.). Furthermore, it does not allow fine-scale management of resource assignment according to the VM’s fluctuating needs. These two concerns have been the focus of the ‘Saline’ and ‘Entropy’ projects, three year projects that aim to manage virtualization environments more dynamically across distributed architectures. Both rely on an encapsulation of each computing task into one or several VMs according to the nature of the task.
Carried out by the MYRIADS team from the INRIA research center in Rennes, France, the Saline proposal focuses on aspects of grid volatility. Through periodic snapshots and a monitoring of the VMs of each task, Saline is able to restart the set of VMs that may malfunction due to a physical failure by resuming latest VM snapshots. Keeping in mind that Saline is still dealing with some restrictions (such as external communications) and considering that a Saline manager is deployed on each site, the resume operations can be performed anywhere in the grid thanks to advanced management of the network configuration of VMs.
Developed by the ASCOLA research group, a joint team between INRIA and the Ecole des Mines de Nantes, France, Entropy is a virtual machine manager for clusters. It acts as an infinite control loop, which performs cluster-wide context switches (i.e. permutation between active and inactive VMs present in one cluster) to provide a globally optimized placement of VMs according to the real usage of physical resources and the scheduler objectives (consolidation, load-balancing etc.). The major advantage concerns the cluster-wide context switch operation that is performed in a minimum number of actions and in the most efficient way.
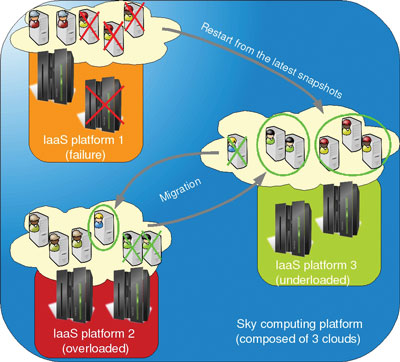
Figure 1: Sky computing platforms composed of three clouds.
The integration of both projects to develop a unique solution started during summer 2010. Our main objective is to combine available mechanisms provided by both systems to deliver an advanced management of virtualized environments across a sky computing platform. Once the VMs are created and uploaded somewhere into the sky, cloud computing users will let this new framework manage their environment throughout the different sites: each set of VMs may “fly” from one cloud to another one according to the allocation policy and the physical changes of the sky. Technically speaking, Saline focuses on the transfer and the reconfiguration of the VMs across the sky, whereas Entropy is in charge of efficiently managing VMs on each cloud. A first prototype is under development and preliminary experiments have been carried out on the Grid’5000 testbed.
Future work will complete the implementation with additional mechanisms provided by virtualization technologies such as emulation and aggregation in order to improve relocation possibilities in the sky, which are currently limited by physical considerations such as processor architecture, size of memory, etc. Finally, our long-term objective is to completely dissociate the vision of resources that each cloud computing user expects from the physical one delivered by the sky. Such a framework will deliver the interface between these two visions by providing first a description language capable of representing user expectations in terms of VMs and second, adequate mechanisms enabling setup and maintenance of this virtual vision in case of physical changes as previously discussed.
Links:
ASCOLA research group: http://www.emn.fr/x-info/ascola
INRIA MYRIADS team: http://www.irisa.fr/myriads
Entropy project: http://entropy.gforge.inria.fr
Please contact:
Jérôme Gallard
INRIA, France
Tel: +33 299 842 556
E-mail:
Adrien Lèbre
Ecole des Mines de Nantes, France
Tel: +33 251 858 243
E-mail:
