








by Rainer Schmidt and Matthias Rella
Researchers at the Austrian Institute of Technology (AIT) are exploring ways to utilize cloud technology for the processing of large media archives. The work is motivated by a strong demand for scalable methods that support the processing of media content such as can be found in archives of broadcasting or memory institutions.
Infrastructure as a Service (IaaS) is a resource provisioning model that enables customers to access large-scale computer infrastructures via services over the Internet. It allows users to remotely host data and deploy individual applications using resources that are leased from infrastructure providers. A major strength of this approach is its broad applicability which is supported by the separation of application implementation and hosting. One of the most prominent frameworks that utilizes the IaaS paradigm for data-intensive computations has been introduced by Google. MapReduce (MR) implements a simple but powerful programming model for the processing of large data sets that can be executed on clusters of commodity computers. The framework targets applications that process large amounts of textual data (as required, for example, when generating a search index), which are parallelized on a master-worker principle. Scalability and robustness are supported through features like distributed and redundant storage, automated load-balancing, and data locality awareness.
Here, we describe a method that exploits MapReduce as the underlying programming model for the processing of large video files. An application has been implemented based on Apache Hadoop, which provides an open-source software framework for data-intensive computing that can be deployed on IaaS resouces. Typical use cases for the processing of archived video materials are for example file format migration, error detection, or pattern recognition. Employing a data-intensive execution platform for video content is desirable in order to cope with the large data volumes and the complexity introduced by diverse file and encoding formats. In previous work, we have developed a service that provides access to clusters of virtualized nodes for processing a large number of relatively small files like documents and images. In this application, parallelization takes place on a per-file basis and the workload is decomposed into a list of file references. During execution, a worker node processes one file for each task, which is retrieved from a shared storage resource. Due to the nature of this problem, the application achieved reasonable speedup when executed within a cluster. Significant IO overhead, however, is introduced by the required file transfer between the compute nodes and the storage service. This necessitates the employment of a strategy that exploits data locality for large data volumes.
File systems like GFS or HDFS are designed to store large amounts of data across a number of physical machines. Files are split into chunks and distributed over the local storage devices of the cluster nodes. This allows the cluster management software to exploit data locality by scheduling tasks closely to the stored content (for example on the same machine or rack). Hence, worker nodes are preferentially assigned to process data that resides within a local partition. The approach has been proven to scale well for the processing of large text files. An interesting question is to explore how it can be applied to binary content as well.
One may consider patter recognition in video files as a data-intensive task. As an example, we have implemented a MapReduce application, which (1) takes a video file as input, (2) executes a face recognition algorithm against the content, and (3) produces an output video that highlights the detected areas.
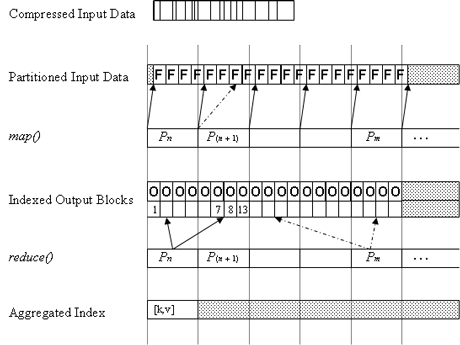
Figure 1: A Distributed MR Video Processing Algorithm.
Video file formats typically provide a container that wraps compressed media tracks like video and audio, as well as metadata. For the pattern matching application, we solely consider the video track, which must be placed on the distributed file system for further processing. This has been done using a custom file format, which creates a raw data stream providing a constant bitrate per frame, as shown in Figure 1. The raw data is automatically partitioned in blocks (64MB) by the file system and dispersed over the physical nodes P. During the first execution phase (map), the cluster nodes are assigned with data portions that correspond to single video frames. In this step, the input frames F are read and pattern recognition takes place. For each frame F, a corresponding output frame O is written and registered within a local index. This index provides key-value pairs that translate between a frame identifier and a pointer to the corresponding data. In an ideal case, each cluster node will only read and write from/to the local data partition. Indexing, however, is required as the data source and order of the frames processed by a cluster node are subject to load balancing and cannot be determined in advance. Also, a minimal data transfer across partitions is required for frames that are split between data partitions. During the second processing phase (reduce), the locally generated index maps are reduced into a single result map. Support is provided by a corresponding driver implementation that directly retrieves the output video stream from the distributed file system based on its index map.
The application has proved to scale well in different test settings. Even small clusters of 3-5 computer nodes have shown performance improvements of up to 50% compared to the execution time of a sequential application.
Link:
http://dme.ait.ac.at/dp
Please contact:
Rainer Schmidt
Austrian Institute of Technology / AARIT
E-mail: