








by Orlando Cassano and Stéphane Mouton
Utility grids are generating increasingly huge amounts of metering information. Grid operators face rising costs and technical hurdles to aggregate and process data. Can Cloud Computing tools, developed notably by Web companies to deal with large data sets, also be used for power grid management?
As electricity in the current state of technology cannot be stored, consumption in power grids is continuously counterbalanced by production. Both producers and consumers are connected to the grid through metered Access Points (AP). Every month, grid operators have to determine the amount of energy produced or used by each stakeholder, knowing that the sum of produced energy, either out of the grid by power plants or within the grid (eg by wind turbines), equals the sum of consumed energy, from effective use and losses in the grid. Amounts are aggregated in order to obtain amount of "allocated" energy by stakeholder. The volume of data at stake in the allocation computation depends on the size of the grid.Data are produced every 15 minutes, and datasets may be huge. For example, there are roughly 8 million APs in Belgium, each producing 96 metering data outputs per day: allocation for a month would therefore require handling of more than 23 billion records.
Data aggregation is currently based on existing Relational DataBase Management Systems (RDBMS). However performance of such software is declining with the increasing volume of data to process. Performance can be improved by investing in hardware and sophisticated software setups, like database clusters, but such an investment is not necessarily economical, with the cost of such a setup increasing disproportionately in relation to data processing capacity.
The goal of our research was to overcome the limitations of RDBMS by scaling performance according to growth of aggregated data. Moreover the allocation algorithm is a good candidate for parallelization as sums have to be performed on distinct data sets, ie, per stakeholder. For this reason we investigated the use of programming platforms and frameworks, identified as providing Platform as a Service (PaaS) on Cloud infrastructures, to enable scalability in data storage and processing.
Data stored in Cloud platforms can be structured in non relational schema following an approach known as NoSQL – standing for Not Only SQL. Major players on the Web use NoSQL databases to deal with large amounts of data such as Google (Bigtable), Amazon (SimpleDB), Facebook (Cassandra), LinkedIn (Voldemort), etc. NoSQL databases follow several approaches:
- Key/Value oriented databases aim to be a simple abstraction for a file system, acting like a hash table.
- Document-oriented databases extend the key/value database concept to add more information to a key (think object oriented).
- Column-oriented databases associate a set of column families with a key. Each column family, containing a variable set of columns to provide a flexible structure for data, will be stored in different machines.
We found that column-oriented databases would fit our needs best. The storage of data by columns is well designed to make aggregations of the same information for all records in the database.
We used the Open Source Hadoop platform for our implementation. Hadoop includes a distributed file system (HDFS) – files are “split” over multiple machines – together with a column-oriented database (HBase).
A parallel algorithm has been written to solve the problem of measurements accounting by aggregating metering information located on slaves. Existing collected data have been ported from the relational database to the NoSQL database. The data have been restructured to fit the column-oriented structure. This implementation provides scalability as well as reliability of the data. Indeed, in the set up cluster, more (cheap) machines can be added dynamically to ensure scalability instead of investing in a new (expensive) big server. In addition, automated redundancy of data, provided by many Cloud platforms (in HDFS in our case), improves reliability.
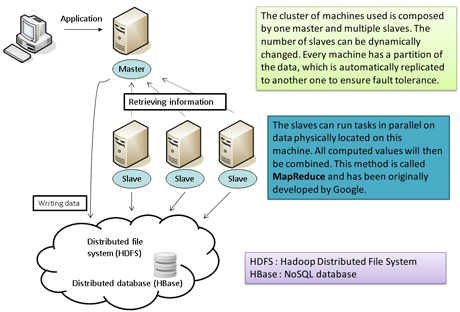
Figure 1: Set up of the Cloud architecture.
Our first results show, however, that performances of our version of the algorithm ported on Cloud platform are lower than the original implementation. We traced the origin of the problem to data structure. Parallelizing processing is not enough: NoSQL databases require full data reorganization. Data structures used in our first implementation are still too oriented towards use of RDBMS and we are currently reworking them and adapting our implementation accordingly. This exercise has enabled us to gain better understanding of the core of the metering aggregation in power grid so as to tailor the corresponding solution more effectively.
We remain confident that we will achieve a speedup by using a Cloud platform, due to the parallel nature of the processing. The problem we faced, however, does raise an issue worthy of consideration: if the required skills or effort necessary to implement NoSQL databases is too high, adoption of this new paradigm could be hampered, and the use of such systems might be restrained to new developments without preexisting use of RDBMS or extreme situations faced by Google or Facebook.
Link:
http://www.cetic.be/article1079.html
Please contact:
Stéphane Mouton
SST-SOA team (SOA & Grid Computing) CETIC, Belgium
Tel: +32 71 490 726
E-mail: