









Delivering a good quality of service is crucial for service providers in cloud computing. Planning the schedule of resource allocations and adapting the schedule to unforeseen events are the primary means of obtaining this goal. Within the EU funded IST project BREIN (Business objective driven reliable and intelligent Grids for real business), semantic and agent technologies have been applied to implement a platform with scheduling, monitoring and adaptation to ensure the agreed quality of service during service provision. In the Department of Distributed Systems of SZTAKI and the Barcelona Supercomputing Centre novel semantic techniques applied in the platform have been developed, namely prediction of quality of service based on historical data and allocation of licenses.
From a business point of view, the service provider establishes an agreement with its customers regarding the Quality of Service (QoS) and level of service through a Service Level Agreement (SLA). The fulfilments or violations of the SLAs indicate the level of customer satisfaction with the Service Provider (SP), affecting directly or indirectly the benefit of these providers. In the cloud environment a service provider can outsource the resources used to execute services to the public cloud. During such outsourcing the allocation mechanism has to cope with the big number of infrastructure providers with their different resource descriptions and the complexity of allocating services to different providers capable of fulfilling the customers’ requirements.
The platform, developed in BREIN for semantic resource allocation, applies a multi-agent system (JADE) to distribute the decisions on resource allocation. The multi-agent technology helps coordinate resource allocation and assists adaptation of service execution, while the semantic web technology helps to leverage interoperability with infrastructure providers.
There are two types of agent in the architecture: Job Agents (JA) are in charge of managing the customers’ executions; and Resource Agents (RA) are in charge of managing the providers’ resources. The scheduling of the jobs in the different resources is made by an agreement obtained from a negotiation between a Job Agent and different Resource Agents. As part of the negotiation, RAs propose allocations according to their provider and the JA selects the allocation proposal most suitable for the customer. During this process agents are supported by two general semantic services: a Semantic Metadata Repository (SMR) containing the current semantic resource descriptions registered in the platform, and the Historical Data Repository (HDR) containing semantically annotated logs from system events such as job executions, failures and other monitoring data.
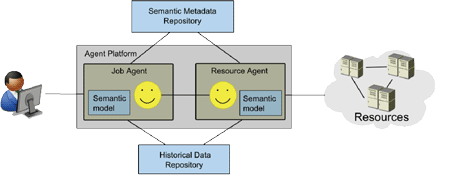
Figure 1: Core architecture for semantic resource allocation.
In order to learn from past experiences, agents use the HDR as a service. On job completion, the Job Agent sends the job execution details to the HDR component. Resource Agents report failures to the HDR. All this information is merged in a single semantic store inside the HDR, enabling the generation of statistics and predictions, created on request by agents during the planning or adaptation of resource allocations. Predictors can be installed as plug-ins for HDR to answer specific questions. Within HDR, the RDF (Resource Description Framework) storage is coupled with data mining software. In this way, a predictor can use both semantic querying and statistical methods. For example, a predictor can build a classification model on top of the results of a semantic query. In real use cases HDR was used to predict delays and failures of job executions, and to assess the reliability of hosts.
Another novel feature of the semantic allocation process is the capability to allocate software licenses for customer requests. The lack of software licenses can block customers’ jobs just as jobs may be blocked by a lack of computing resources. However, software license allocation is regulated by quite different rules than computing resource allocation. There exists a huge variety of license restrictions, and thus the machine understandable representation of licenses is a huge and difficult task. In order to provide a practical solution for frequent use cases, we limited the semantic descriptions to the viewpoint of resource management, and compiled an extensible core for the semantic description of software licenses, where issues raised by new types of license can be covered by new rules plugged into the running environment. With this approach we successfully modelled license term restrictions on CPU numbers, temporal limitations, user limitations, and hosts running the software. During license allocation, the set of suitable licenses for a client request is created and filtered by a customizable rule set within the Jena Semantic Web toolkit, where finally only the applicable licenses are sent to the Job Agent for final selection and allocation.
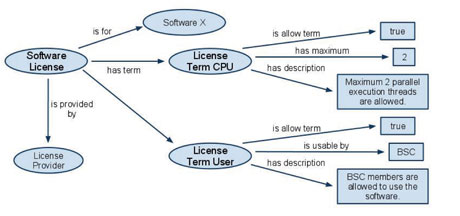
Figure 2: Example for a software license description.
The BREIN project team extended and connected a set of ontologies in order to support the mentioned functionalities. Based on OWL-S and the Grid Resource Ontology (GRO) we created an OWL-DL environment in which business and technical aspects of service provisioning can be described and related to each other.
BSC and SZTAKI have jointly developed the two new features detailed here, and plan to continue to test more real-life use cases and to further extend the use of semantic techniques in adaptable resource allocation and job scheduling.
Link:
http://www.eu-brein.com/
Please contact:
András Micsik
SZTAKI, Hungary
Tel: +36 1 279 6248
E-mail:
Jorge Ejarque - Barcelona Supercomputing Center, Spain,
Tel: +34 934137248
E-mail:
