









by Sven Söhnlein and Francesca Saglietti
Statistical testing represents a well-founded approach to the estimation of software reliability. Its major drawback - namely the prohibitive testing effort it usually requires - can be overcome by efficient exploitation of operational evidence gained with pre-developed software components and by the loss-free combination of component-specific reliability estimates.
The application of software systems in safety-critical environments requires that prescribed reliability targets are demonstrated using extremely rigorous verification and validation procedures. For such systems, statistical testing offers an adequately well-founded approach. While the effort required to apply this technique at a system level may lead to prohibitively extensive testing phases, this can be largely mitigated by the exploitation of past testing and/or operational experience gained with individual components or functionalities.
The potential usefulness of assessing the operational evidence gained with software-based applications is arousing the interest of developers in different industrial domains, especially concerning application variants based on pre-developed components. Among them, the automotive industry plays a major role; a study is being conducted on software reliability assessments tailored to its particular needs, and making use of the considerations presented in this article.
Statistical sampling theory allows - for any given confidence level ß and sufficiently large amount n of correct operational runs (say n > 100) - an upper bound of the failure probability p to be derived, assuming the following testing pre-conditions are fulfilled:
- The selection of a test case does not influence the selection of further test cases.
- The execution of a test case does not influence the outcome of further test cases.
- Test cases are selected in accordance with the expected frequency of occurrence during operation.
- No failure occurs during the execution of any of the test cases selected (a more general sampling theory allows for a low number of failure observations).
- Failure probability can be expected to be approximately invariant over the input space (may be taken as realistic for software components of restricted functionality).
Under these conditions, statistical sampling theory allows the following conservative reliability estimate to be derived at confidence level b:
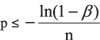
For the purpose of applying this theory to operational data gained with software components, the latter must be recorded, analysed and appropriately filtered. A practicable procedure for extracting relevant operational information is currently applied within an industrial research project using a software-based automatic gear control system. This is structured as follows:
1. Delimitation of scope
- identification of software functionality to be used to assess reliability
- modelling of operational runs including only input parameters relevant to the functionality considered.
2. Analysis of operational experience
- identification of memory-less suites, ie sequences of runs whose behaviour does not depend on history
- determination of frequency of functional demands during operation
- extraction of an operationally representative subset of independent operational data.
3. Assessment of operational evidence
- validation of extracted operational evidence with respect to identification of incorrect runs
- assessment of software reliability by statistical sampling theory (as illustrated above)
- if required, extension of operational experience in order to validate a prescribed reliability target.
The economics of this approach are particularly appealing in the case of pre-developed components for which a certain amount of operational data may already have been collected in the context of past applications. Once interpreted in the light of their future operational profile, the statistical analysis of such operational data yields (as illustrated above) a conservative reliability estimate for each reusable functionality considered.
For component-based systems consisting of a number of such pre-developed functionalities, the assessor is still faced with the problem of combining several component-specific reliability inequalities into one overall conservative system reliability estimate of high significance. State-of-the-art combination approaches based on mere superimposition of inequalities provoke a substantial reduction in confidence.
Ongoing work aims to improve this situation by providing sharp reliability estimates. This was recently achieved for the special case of parallel component-based architectures (see link below). Thanks to the accurate estimation, the newly developed technique allows a substantial reduction in the amount of operational experience required to demonstrate a prescribed reliability target.
Link:
http://www11.informatik.uni-erlangen.de/Forschung/Projekte/CORE/eng_index.html
Please contact:
Sven Söhnlein, Francesca Saglietti
University of Erlangen-Nuremberg, Germany
E-mail: {soehnlein, saglietti} informatik.uni-erlangen.de
informatik.uni-erlangen.de
