









by Christian Beecks (FernUniversität in Hagen) and Markus Lange-Hegermann (Technische Hochschule Ostwestfalen-Lippe)
Data-driven scientific discovery increasingly relies on artificial intelligence. This article presents a human-centred data science framework based on Gaussian process models which enable the extraction of interpretable, uncertainty-aware insights while keeping the data scientist in control of the discovery process.
Data science is a modern scientific discipline that researches data-analytical methods for complex problem solving. Being positioned at the frontiers across math, computer science, and artificial intelligence, data science has evolved into an interdisciplinary methodology for data-driven scientific discovery. This new era of scientific discovery, which is also known as the fourth paradigm of science [1], is characterized by big versatile data landscapes and advanced analysis methods from the fields of machine learning and artificial intelligence. Revealing actionable and interpretable insights from big data and complex algorithms is hence one of the major challenges in data science.
Apart from these challenges, the interdisciplinary nature of data-driven scientific discovery necessitates an efficient means of implementation. While a broad range of data technologies and analysis methods are domain-agnostic, the scientist’s aims and abilities are crucial when designing a data-driven solution to a specific data scientific problem. Prior knowledge and domain expertise are a prerequisite when narrowing down the data analytical solution space to apt machine learning models and artificial intelligence methods.
The process of data-driven scientific discovery typically requires extensive manual effort. Following the conceptual analysis workflow of the data science life cycle [2], data first undergoes cleaning, preparation and exploratory analysis before statistical inference and model estimation are adopted to domain-specific research questions. Though automated machine learning approaches have mitigated the time-consuming task of building, tuning and deploying machine learning models, these approaches follow a strictly formalised objective function, making it difficult to uncover insights hidden in the data.
The extraction of interpretable and, where appropriate, actionable insights is one of the greatest data science capabilities, particularly when applied in an open-ended manner, where the research question or hypotheses need to be first developed and then empirically verified. In this case of scientific discovery, structured hypotheses based on data effects and hidden phenomena, such as trends and correlations as well as dependencies and causalities need to be determined efficiently based on limited human effort. To mitigate information complexity during this process, raw data is typically abstracted by means of data models. Among the broad variety of data models, such as symbolic regression, simple causal models and interpretable regression models, Gaussian process models have turned into a general-purpose model widely used in Bayesian machine learning. Not only their stochastic nature, but also their ability to dynamically cope with incomplete and uncertain data in an interpretable way, shows that Gaussian processes are well suited for trustworthy data-driven scientific discoveries.
Our aim is to exploit Gaussian process models for the development of a trustworthy and interpretable approach to data-driven scientific discovery. While recent methods towards data science automation make extensive use of large language models [3], we aim to exploit a clear Bayesian formalism by means of Gaussian process to (i) model data in an optimal way, (ii) derive transparent analytical insights, and (iii) deliver comprehensible explanations. These three pillars define a new human-centred perspective on data science that epitomizes a trustworthy and interpretable approach for data-driven scientific discovery.
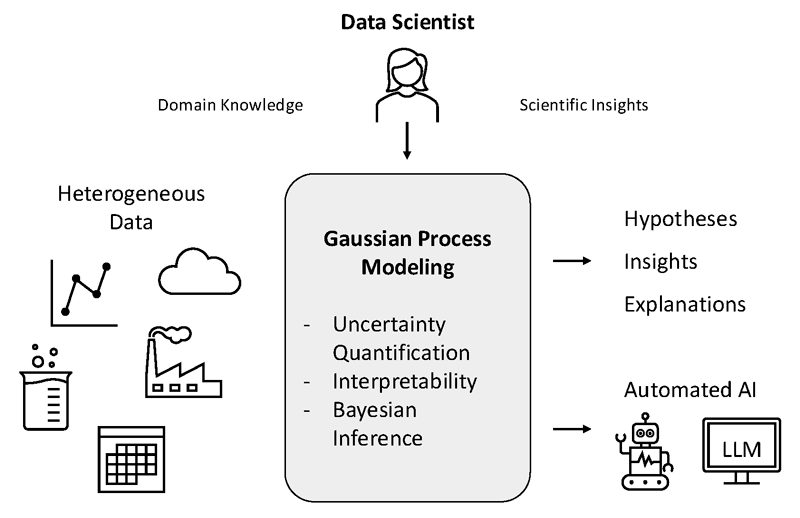
Figure 1: Human-centred framework for trustworthy AI in data-driven scientific discovery. Gaussian process models form an interpretable and uncertainty-aware core that connects heterogeneous data sources with scientific insights, while allowing human experts to guide hypothesis generation, model refinement, and interpretation. Automated AI components support analytical tasks without replacing human control.
Coming back to its origin, the last decade has advanced data science from a code-centric approach, where data scientists act as programmers implementing analytical operations line-by-line, to a no-to-low-code approach, where data scientists leverage automation frameworks powered by automated machine learning to perform analytical operations. Based on scientific innovations in the field of generative artificial intelligence, data science has evolved into an artificial intelligence-driven approach [3], where agentic systems orchestrated by large language models try to guess the data scientist’s intention and execute analytical operations. While the latter approaches show remarkable performance in typical data science tasks ranging from data preparation to report generation, they are also able to conduct deep research on diverse data sources [3].
Against this background, we propose a methodological framework that makes use of Gaussian process models as a core component for trustworthy data-driven scientific discovery. Instead of replacing the data scientist with fully automated agentic systems, our approach augments human expertise by providing transparent probabilistic models that support hypothesis generation, validation, and exploitation. By explicitly quantifying uncertainty and enabling interpretable model structures, Gaussian processes allow data scientists to explore complex data landscapes while maintaining control over analytical decisions. This combination of Bayesian inference and human-centred artificial intelligence fosters reproducible insights and supports responsible scientific discovery across diverse application domains.
References:
[1] S. Tansley and K. M. Tolle, The Fourth Paradigm: Data-Intensive Scientific Discovery, T. Hey, Ed. Redmond, WA, USA: Microsoft Research, 2009.
[2] V. Stodden, “The data science life cycle: A disciplined approach to advancing data science as a science,” Commun. ACM, vol. 63, no. 7, pp. 58–66, Jul. 2020.
[3] S. Zhang et al., “DeepAnalyze: Agentic large language models for autonomous data science,” arXiv preprint, arXiv:2510.16872, 2025.
Please contact:
Christian Beecks
FernUniversität in Hagen, Germany
Markus Lange-Hegermann
Technische Hochschule Ostwestfalen-Lippe, Germany

