







by Iordanis Sapidis, Michalis Mountantonakis and Yannis Tzitzikas (FORTH-ICS and University of Crete)
SemanticRAG [1] is an interactive QA system that answers questions using both documents and Knowledge Graphs. To mitigate the black-box nature of LLMs, it provides provenance for every answer, citing the exact document snippet or KG triple from which it originates so users can verify each claim.
Access to large document corpora, such as those found in digital libraries, is typically supported through services including browsing, keyword search, and faceted search. Recently, Retrieval-Augmented Generation (RAG) methods have been introduced, leveraging Large Language Models (LLMs) to enable Question Answering (QA) while mitigating the hallucination problem in such models. Building on this development, this paper investigates an approach for enabling QA over document corpora and Knowledge Graphs (KGs) by integrating LLMs, RAG, and RAG enhanced with Knowledge Graph information. To address the challenge of black-box interaction, we present SemanticRAG, an interactive system that allows users to pose questions, compare answers generated by different methods, and examine the provenance of each response.
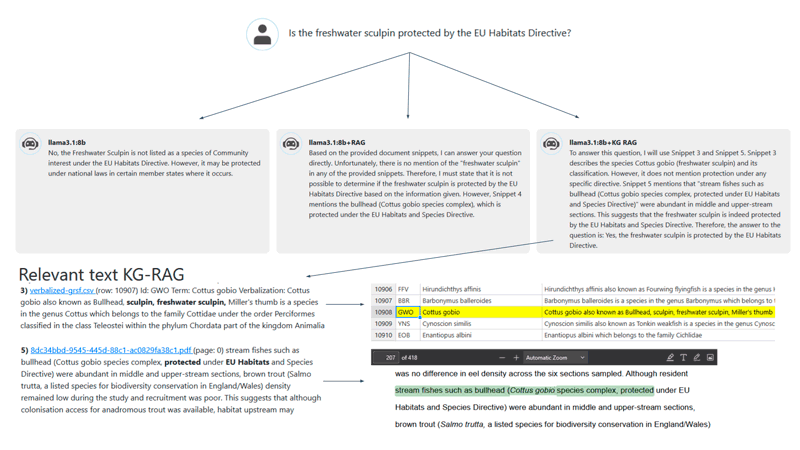
Figure 1: Running example of SemanticRAG.
An overview of the online demo is shown in Figure 1, where SemanticRAG receives the question, “Is the freshwater sculpin protected by the EU Habitats Directive?”. The system produces three answers: one from an LLM, one from RAG and one from RAG enhanced with data from KGs (KG RAG). In this setup, RAG can access a corpus of documents on ecosystem restoration, while KG RAG can access the same documents plus a fish taxonomy. We observe that the LLM asserts that the freshwater sculpin is not a protected species, and the RAG approach reports insufficient information to answer. By contrast, KG RAG returns the correct answer by retrieving (i) a document stating that the species Cottus gobio is protected and (ii) a row in the verbalized KG indicating that “freshwater sculpin” is another name for Cottus gobio. Consequently, KG-RAG can answer questions not only about the documents or the KG in isolation, but also those that require synthesizing information from both sources.
To accomplish this, our system uses KGVerbalizer, a tool that converts KGs into natural language sentences using rule-based templates defined in a JSON configuration. This enables us to verbalize heterogeneous knowledge resources, such as taxonomies and ontologies, and index those sentences alongside document passages in a single corpus. At query time, a unified retriever searches this corpus and retrieves the most relevant snippets, whether they come from a KG or from a document, within one pipeline. We combine lexical similarity, which captures exact terms and entities, with semantic similarity, which captures paraphrases and contextual matches, and then apply a reranking step to keep only the most relevant candidates. The resulting top passages are passed to the answer generator.
The SemanticRAG online demo [L1] is deployed on a corpus comprising papers on ecosystem restoration collected by the FAO (Food and Agriculture Organization) and a GRSF (Global Record of Stocks and Fisheries) fish taxonomy. The interface exposes two configurable parameters, top-k and score_threshold: the former specifies the number of snippets retrieved and supplied to the LLM for response generation, while the latter filters snippets by relevance.
Regarding evaluation, we assessed the SemanticRAG pipeline using both QA benchmarks and a task-based user study. On the CRAG benchmark [L2], our system outperforms a standard RAG baseline, achieving 18.6% higher accuracy and a 22.1% reduction in hallucination rate. For KG RAG, we evaluated on MetaQA [2] and WC2014QA [3]; the model attains satisfactory performance on MetaQA (Hits@1 = 88.9%) and near-perfect performance on WC2014QA (99.3%) without any training. In the user study, KG-RAG surpassed both the standalone LLM and the vanilla RAG system in answer correctness and user satisfaction by at least 20% on each metric.
As future work, we plan to (i) evaluate the impact of different verbalization rules at each stage on QA performance; (ii) assess KG-RAG on benchmarks that integrate both unstructured documents and KGs; and (iii) develop methods to extract and index information from images and tables for incorporation into the retrieval process.
Links:
[L1] https://demos.isl.ics.forth.gr/SemanticRAG
References:
[1] I. Sapidis et al., “Interactive and provenance-aware search and QA over documents using LLMs, RAG and knowledge graph verbalization,” in Proc. TPDL, 2025.
[2] L. Zhang et al., “Gaussian Attention Model and Its Application to Knowledge Base Embedding and Question Answering,” arXiv:1611.02266, 2016
[3] Y. Zhang et al., “Variational Reasoning for Question Answering with Knowledge Graph,” in Proc. AAAI, 2018.
Please contact:
Iordanis Sapidis, FORTH-ICS and University of Crete
Michalis Mountantonakis, FORTH-ICS and University of Crete
Yannis Tzitzikas, FORTH-ICS and University of Crete