









by Mark Cieliebak (Zurich University of Applied Sciences)
Deep Neural Networks (DNN) can achieve excellent results in text analytics tasks such as sentiment analysis, topic detection and entity extraction. In many cases they even come close to human performance. To achieve this, however, they are highly-optimised for one specific task, and a huge amount of human effort is usually needed to design a DNN for a new task. With DeepText, we will develop a software pipeline that can solve arbitrary text analytics tasks with DNNs with minimal human input.
Assume you want to build a software for automatic sentiment analysis: given a text such as a Twitter message, the tool should decide whether the text is positive, negative, or neutral. Until recently, typical solutions used a feature-based approach with classical machine learning algorithms (e.g., SVMs). Typical features were number of positive/negative words, n-grams, text length, negation words, part-of-speech tags etc. Over the last two decades a huge amount of research has been invested in designing and optimising these features, and new features had to be developed for each new task.
With the advent of deep learning, the situation has changed: now the computer is able to learn relevant features from the texts by itself, given enough training data. Solving a task like sentiment analysis now requires three major steps: define the architecture of the deep neural network; aggregate enough training data (labelled and unlabelled); and train and optimise the parameters of the network.
For instance, Figure 1 shows the architecture of a system that won Task 4 of SemEval 2016, an international competition for sentiment analysis on Twitter [1]. This system uses a combination of established techniques in deep learning: word embedding and convolutional neural networks. Its success is primarily based on three factors: a proper architecture, a huge amount of training data (literally billions of tweets), and a huge amount of computational power to optimise its parameters. Live demos of various deep learning technologies are available at [2].
![Figure 1: Deep nNeural nNetwork for sSentiment aAnalysis [1].](/images/stories/EN107/cielbak1.png)
Figure 1: Deep nNeural nNetwork for sSentiment aAnalysis [1].
Goal of DeepText
In DeepText, we will automate the three steps above as far as possible. The ultimate goal is a software pipeline that works as follows (see Figure 2):
- The user uploads his or her training data in a standard format. The data can consist of unlabelled texts (for pre-training) and labelled texts, and the labels implicitly define the task to solve.
- The system defines several DNNs to solve the task. Here, different fundamental architectures will be used, such as convolutional or recurrent neural networks.
- The system then trains these DNNs and optimises their parameters.
- Performance of each DNN is measured, e.g. in terms of F1-score, and the best DNN is selected.
- Finally, the system wraps the “winning” DNN into a software library with a simple interface. This library is ready-to-use in production.
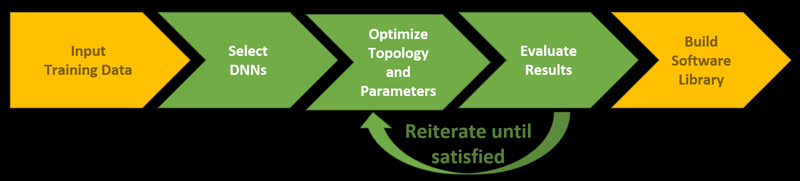
Figure 2: Generating a software library for arbitrary text understanding tasks.
In principle, only the first step – collecting and labelling the training data – needs to be done by humans, since this step defines which task should be solved, and how. For instance, for sentiment analysis on Twitter, each text is labelled with positive, negative, or neutral; on the other hand, if we want to detect companies or persons in text (“entity recognition”), then the proper position of each occurrence of an entity within the text needs to be labelled.
The last three steps in the process above are straightforward, and basically require substantial computational resources and appropriate skills in software engineering.
Challenge: Find a good DNN architecture
The most challenging part is Step 2: to come up with “appropriate” DNNs for the task at hand. There exist several established DNN architectures for text analytics, such as convolutional neural networks (CNNs) or recurrent neural networks (RNNs). For each architecture, there exist various parameters: in the case of CNNs, this is the number of convolutional layers, size and number of filters, number and type of pooling layers, ordering of the layers etc. In theory, each configuration of a DNN could be used, but this would lead to an explosion of DNNs to evaluate.
For this reason, we will develop several template DNNs for different types of text analytics tasks: classification, topic detection, information extraction etc. Based on these templates, the system will run a pre-training where each template is applied to the task at hand and evaluated. Only the most promising DNNs will then be used for parameter tuning and optimisation.
Our goal is that, given the training data, the system will generate a suitable software library within three days.
About the Project
Deep Text is an applied research project of Zurich University of Applied Sciences (ZHAW) and SpinningBytes AG, a Swiss startup for data analytics. It started in 2016 and is funded by the Commission for Technology and Innovation (CTI) in Switzerland (No. 18832.1 PFES-ES).
Link:
[L1] http://spinningbytes.com/demos/
Reference:
[1] J. Deriu et al.: “SwissCheese at SemEval 2016 Task 4”, SemEval (2016).
Please contact:
Mark Cieliebak
School of Engineering, Zurich University of Applied Sciences (ZHAW) , Switzerland
+41 58 934 72 39

