









by Karol Kurach (University of Warsaw and Google), Marcin Andrychowicz and Ilya Sutskever (OpenAI (work done while at Google))
We propose “Neural Random Access Machine”, a new neural network architecture inspired by Neural Turing Machines. Our architecture can manipulate and dereference pointers to an external variable-size random-access memory. Our results show that the proposed model can learn to solve algorithmic tasks and is capable of discovering simple data structures like linked-lists and binary trees. For a subset of tasks, the learned solutions generalise to sequences of arbitrary length.
Recurrent Neural Networks (RNNs) have recently proven to be very successful in real-world tasks, like machine translation and computer vision. However, success has been achieved only on tasks which do not require a large memory to solve the problem, e.g., we can translate sentences using RNNs, but we cannot produce reasonable translations of really long pieces of text, like books. A high-capacity memory is a crucial component to deal with large-scale problems that contain multiple long-range dependencies.
Currently used RNNs do not scale well to larger memories, e.g., the number of parameters in a popular LSTM architecture [1] grows quadratically with the size of the network’s memory. Ideally, the size of the memory would be independent of the number of model parameters. The first versatile and highly successful architecture with this property was the Neural Turing Machine (NTM) [2]. The main idea behind the NTM is to split the network into a trainable ‘controller’ and an ‘external’ variable-size memory.
In our paper Neural Random-Access Machines [3] we propose a neural architecture inspired by the NTM. The Neural Random-Access Machine (NRAM) is a computationally-universal model employing an external memory, whose size does not depend on how many parameters the model has. It has, as primitive operations, the ability to manipulate, store in memory, and dereference pointers into its working memory. The pointers in our architectures are represented as distribution over all memory cells. That is, the memory consisting of M cells is an MxM matrix, where each row fulfils probability conditions (all elements are non-negative and sum to 1). This trick allows our model to be fully differentiable and the standard backpropagation algorithm can be used to train it.
Figure 1 gives an overview of the model. NRAM consists of a neural network controller, memory, registers and a set of built-in operations (such as number addition and comparison). An operation can either read (a subset of) contents from the memory, write content to the memory or perform an arithmetic operation on either input registers or outputs from other operations. The controller runs for a fixed number of time steps. At every step, the model selects both the operation to be executed and its inputs. To make this step differentiable, we are using soft attention – each operation is given a linear combination of the inputs, where weights of this linear combination can be controlled by the network. Among other novel techniques, our model employs a differentiable mechanism for deciding when to stop the computation.
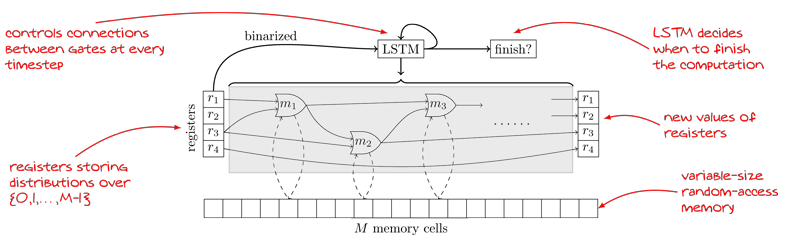
Figure 1: One timestep of the NRAM architecture with 4 registers. The weights of the solid thin connections are outputted by the controller. The weights of the solid thick connections are trainable parameters of the model. Some of the modules (i.e. READ and WRITE) may interact with the memory tape (dashed connections).
By providing our model with dereferencing as a primitive, it becomes possible to train it on problems whose solutions require pointer manipulation and chasing. It has learned to solve algorithmic tasks and is capable of learning the concept of data structures that require pointers, like linked-lists and binary trees. For a subset of tasks, we show that the found solution can generalise to sequences of arbitrary length. Moreover, memory access during inference can be done in a constant time under some assumptions.
Finally, one may well ask: why train a network to solve a task for which people already know the optimal solution? One reason is that a powerful neural architecture, capable of learning sophisticated algorithms, should be also be able to learn solutions (or approximations) for complex tasks for which we do not yet know algorithms. We also believe that algorithmic reasoning is one of the necessary (and missing) components in the design of systems able to solve a wide range of real-world problems. The presented model is a step in this direction.
References:
[1] S. Hochreiter, J. Schmidhuber “Long short-term memory”, Neural Computation, Vol 9 Issue 8, pp 1735-1780, MIT Press Cambridge, MA, USA, 1997
[2] A. Graves et al.: “Neural Turing Machines”, CoRR, 2014
http://arxiv.org/abs/1410.5401
[3] K. Kurach et al. “Neural Random-Access Machines”, ICLR 2016, http://arxiv.org/abs/1511.06392
Please contact:
Karol Kurach, University of Warsaw and Google, Poland

