









by Jacco van Ossenbruggen
Professional users in the heritage domain have started to deploy data published on the Web: data that often comes in different forms, from different sources and is controlled by different organizations. In addition to the data integration problems in the back end, CWI is also studying the user interface challenges in the front end.
In the context of the Dutch MultimediaN e-culture project, we have been looking at ICT-related tasks of professional users from the cultural heritage domain. Many of these tasks are now performed by using a single information source at a time, typically a web site of a trusted organization or, more often, on "in house" data: data collected and curated either by the users themselves or their direct colleagues working in the same institute. For our research, we selected tasks that could obviously benefit from including multiple data sources, especially if those sources were publically available from the Web. We then looked at the implications of this shift from single source, trusted data to multiple source, untrusted data had on the user interface.
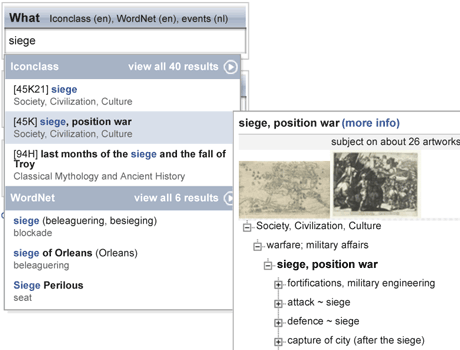
Figure 1: Art annotation application developed by CWI in cooperation with the Rijksmuseum. While the user is typing, the interface suggests terms from different public web data sources, in this case RKD's IconClass and Princeton's WordNet.
One thing we learned is that heritage data is never ‘sound and complete’. Even well-curated data sets of any substantial size contain many omissions, imprecise values and plain errors. However, in practice, in the single source setting, this hardly seems an issue: users typically know what is in ‘their’ database and what is not, and which parts of the data are in line with the institute's guidelines and which parts are not. Users take this into account, for example, when performing search tasks in a museum's collection management system. Our team at CWI conducted several user experiments, asking heritage professionals to think aloud during their search tasks. Remarks along the lines of: "You would think I could just search on this keyword, but I know this part of the collection has not been properly annotated yet, so instead I will ..." clearly indicate that users explicitly work around the problems in their data.
However, this situation completely changed when we confronted users with similar quality issues in data sets they were either unfamiliar or less familiar with. For example, the same type of errors users seamlessly worked around in a single source setting, often led to confusion in experiments with multiple data sources. Even worse, when our prototypes revealed conflicting claims about the same art object or artist without explaining the source or provenance of these claims, it led to users totally distrusting the entire system.
Another striking example was a prototype annotation interface we developed to enter metadata of artworks as part of a museum's collection registration process. We studied this process extensively in the print room of the Rijksmuseum in Amsterdam, where literally hundreds of thousands of historical prints are currently being digitized and described. In the single source setting, one specific interface worked fine because it was optimized for finding, as quickly as possible, an artist's name that the user knew to be in the database: it ranked search results by frequency of use. The same interface, however, proved useless in the multiple source setting, because now the frequency-based ranking made it impossible to judge whether a specific artist was not present at all or was just ranked too low to appear in the top-N search results presented. In the multiple source setting, a simple alphabetically ordered list of search results proved to work much better than the frequency-based ranking.
These and other insights of the MultimediaN E-culture project are now being used in the Europeana project. The issues around dealing with varying data quality in the user interface will only become more relevant now more and more user generated content finds its way into the cultu ral heritage field. The successor of MultimediaN, the Dutch national research project COMMIT, will start this summer. This project will focus on provenance of, and trust in, curated and non-curated heritage data as one of its key research topics. These topics also apply to domains other than cultural heritage.
In the European Fish4knowledge project, CWI is studying the interface implications of data quality in large scale data observations of coral reef fish. Since the database is filled with observations made by automatic feature detectors analyzing large quantities of underwater video camera footage, the quality of the data varies with the quality of the detection algorithms used, the turbidity of the water, the movement of the fish, etc. How to convey the strengths and limitations of this data without overwhelming biologists with the technical details of automatic video analysis algorithms is one of the challenges in this project.
Links:
http://e-culture.multimedian.nl/
http://www.europeana.eu/
http://www.commit-nl.nl/
http://www.fish4knowledge.org/
Please contact:
Jacco van Ossenbruggen, CWI, The Netherlands
Tel: +31 20 592 4141
E-mail:
