








by Dávid G. Nagy, Csenge Fráter and Gergő Orbán (Wigner Research Center for Physics)
Efficient compression algorithms for visual data lose information for curbing storage capacity requirements. An implicit optimisation goal for constructing a successful compression algorithm is to keep compression artifacts unnoticed, i.e., reconstructions should appear to the human eye to be identical to the original data. Understanding what aspects of stimulus statistics human perception and memory are sensitive to can be illuminating for the next generation of compression algorithms. New machine learning technologies promise fresh insights into how to chart the sensitivity of memory to misleading distortions and consequently lay down the principles for efficient data compression.
Humans are prone to errors when it comes to recollecting details about past experiences. Much research has addressed the questions of which details our memory chooses to store and which are systematically discarded. Until recently we have not had methods to learn the complex statistics to which memory has adapted to (natural statistics) so there is little data available about how these systematic failures link to natural stimulus structure.
Researchers at the Wigner Research Center for Physics, Budapest, have addressed this challenge using variational autoencoders, a new method in machine learning that learns a latent variable generative model of the data statistics in an unsupervised manner [1]. Latent variable generative models aim to identify the features that contribute to the generation of the data and every single data point is encoded as a combination of these features. The proposed semantic compression idea establishes how to distinguish compression artefacts that go unnoticed from those that are more easily detected: artefacts that induce changes in the latent features are more easily noticed than artefacts of equal strength that leave the latent features unchanged. The theory of semantic compression was put to a test by revisiting results from human memory experiments in a wide array of domains (recollection of words, chess board configurations, or drawings) and showing that semantic compression can predict how memory fails under a variety of conditions.
Using generative models to encode complex stimuli offers new perspectives for compression. The power of these generative models lies in the fact that the latent features discovered by the generative model provide a concise description of the data and are inherently empowered by reconstruction capabilities [2]: in contrast to more traditional deep learning models, variational autoencoders are optimised for efficient reconstruction ability. Nonlinear encoding is thus a way to build ultra-low bit-rate data compression technologies. This “generative compression” idea is boosted by two critical factors that concern two qualitatively different aspects of data compression. First, recent work in the field has demonstrated a tight link between variational autoencoders and the theory of lossy compression [3]. This link demonstrates that VAEs are optimised for the same training objective as the theory that establishes the optimality criterion for lossy compression. In fact, a continuum of optimal compressions can be established, depending on the allowed storage capacity, thus different generative models can be constructed for different needs. Second, research by Nagy et al. provides support that the structure of errors that generative compression is sensitive to is similar to the structure of errors that memory is sensitive to. Theory claims that this is not simply a lucky coincidence: the basis of it is that the generative model is trained on stimulus statistics that are designed to approximate the statistics that the human brain was adapted to.
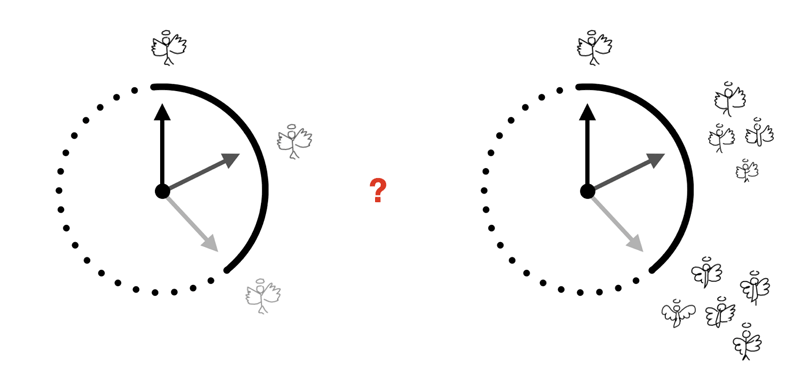
Figure 1: The dynamics of forgetting: memory undergoes changes and information is systematically discarded over time, which provides insights into the sensitivities of memory. An account of information loss would be to simply lose memory through “fading”: uniformly losing precision when reconstructing episodes from memory. Instead of such non-specific information loss, compression with latent-variable generative models implies that reconstruction errors reflect uncertainty in latent features. As the delay between encoding and recollection increases, latent variable representation of the stimulus is reshaped and we can capture signatures of lower-rate compressions.
In the context of human memory, the study highlights a fascinating view. We are all too aware that memories undergo disappointing dynamics that result in what we call “forgetting”. Is the gradual process of forgetting best understood as a simple process of fading? The answer the authors provide could be more appropriately described as memories become less elaborate as time passes: the theory of lossy compression establishes a harsh trade-off between storage allowance and the richness of the retained details. As time passes it is assumed that the capacity allocated for a memory decreases and details are lost with stronger compression. And what are the details that remain? Those are again determined by stimulus statistics: features that are closer to the gist of the memory prevail while specific details disappear.
References:
[1] D.G. Nagy, B. Török, G. Orbán: “Optimal forgetting: Semantic compression of episodic memories”, PLoS Comp Biol, e1008367, 2020.
[2] I. Higgins I, et al.: “beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework”, Proc. of ICLR, 2018.
[3] A. Alemi, et al.: “An information-theoretic analysis of deep latent-variable models”, arXiv:1711:00464.
Please contact:
Gergő Orbán
Computational Systems Neuroscience Lab, Dept. of Computational Sciences, Wigner Research Center for Physics, Hungary

