









by Mohammad Shahid, Torbjoern Klatt, Hassan Rasheed, Oliver Wäldrich and Wolfgang Ziegler
One of the major challenges of in-silico virtual screening pipelines is dealing with increasing complexity of large scale data management along with efficiently fulfilling the high throughput computing demands. Despite the new workflow tools and technologies available in the area of computational chemistry, efforts in effective data management and efficient post-processing strategies are still ongoing. SCAI-VHTS fully automates virtual screening tasks on distributed computing resources to achieve maximum efficiency and to reduce the complexities involved in pre- and post-processing of large volumes of virtual screening data.
Virtual screening is an important and complementary step in the modern drug discovery process. Small molecules in virtual compound databases are computationally screened against specific biological protein targets by computing the binding energy of these molecules inside the protein active site. Scoring and ranking is performed to filter and select drug-like molecules, which are active against the biological targets of interest. The three dimensional structures of both the protein targets and small molecules are required to perform virtual screening in the structure based drug discovery process. There are more than 60,000 protein 3D structures available in the Protein Data Bank (PDB) and millions of small molecules in compound databases, which are publicly available. Furthermore, there are billions of virtual compounds that could be obtained from combinatorial chemistry space. Even simulating a few million of such large datasets increases the demand for computing resources, as well as the effort involved with management of large datasets.
Without a framework that fully automates the virtual screening workflow, manual execution and management of the workflow is very cumbersome. First, there is the subtle issue of handling huge amounts of data in the form of large numbers of input/output files. Data management during pre- and post-processing stages is the most tedious, laborious and time-consuming work. Other important issues include the manual distribution of the workload on the available computing resources, and tracking and monitoring of the running tasks. Furthermore, fault tolerance is an important issue that requires great effort in failure management, including identification and resubmission of tasks that are failed or lost for various reasons.
Many recent research projects have been demonstrating the role and relevance of using Grid technologies for virtual screening. Grid technologies can help accelerate the screening process as well as providing required resources such as computing power and large scale data storage that meet the demands of CPU- and data-intensive biomedical applications. In research environments Grids are established as a useful technology that allows sharing and on demand utilisation of geographically dispersed heterogeneous resources including high performance computing resources. Grid technologies are applied to perform high throughput computation in the computational chemistry domain. The use of this technology enables researchers to collaborate in a virtual laboratory that provides an integrated resource platform. A framework for integrating tools and methodologies for efficient deployment of virtual screening experiments forms the basis of such a virtual screening laboratory.
SCAI-VHTS, a fully automated virtual high throughput screening framework, enables the researchers to perform large scale virtual screening experiments that include complex workflows with great ease of use. The framework is based on the functionalities provided by the UNICORE Grid middleware, together with SCAI’s Meta Scheduling Service extended in the PHOSPHORUS project (see links below). A virtual screening workflow typically consists of pre-processing the input data, the distribution of the data to the computing systems, execution of the screening applications that perform simulations, post-processing and collection of the results. The architecture of the automated virtual screening framework (see Figure 1) provides a single point of interaction to distributed computing resources while hiding the complexity of the underlying infrastructure.
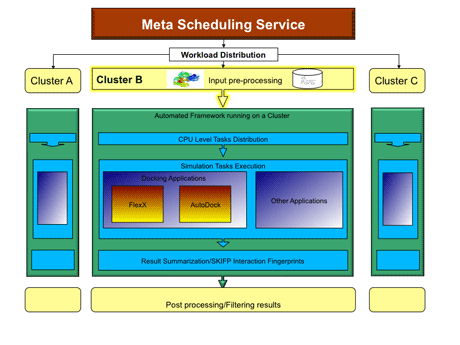
Figure 1: Architecture of the automated virtual screening framework.
Within this framework two compute and data intensive applications FlexX and AutoDock have been integrated with the components for performing pre-processing of the input data as well post-processing of the results. Pre-processing includes formatting the input data for the respective application while post-processing includes filtering of virtual screening results by applying post-docking strategies. Post-processing is mainly comprised of ranking by the built-in scoring function of the application as well as re-ranking by a modified protein-ligand interaction fingerprints approach.
The researcher simply has to submit a single virtual screening job on the Grid through a graphical UNICORE client plug-in, after which the Meta Scheduling Service performs work load distribution, manages execution and monitoring on the computing resources available. Wrapper programs configured locally on the compute clusters further facilitate maximum utilisation of the compute resources as well as the management of the distributed virtual screening data. The modular workflow is fully extensible to allow easy integration of other applications such as molecular dynamics simulations.
The SCAI-VHTS framework relieves the researcher from dealing with the challenges of deploying large scale virtual screening experiments and the tedious and laborious work involved in management of large volumes of input/output data. As a result, the researcher can concentrate on his primary goals: finding and evaluating new drugs. SCAI-VHTS can assist with data management, analysis, and automated knowledge discovery by facilitating remote collaborations of distributed and heterogeneous Grid resources, thus creating a virtual laboratory for biological research and development.
Links:
UNICORE: http://www.unicore.eu
PHOSPHORUS: http://www.ist-phosphorus.eu/
Please contact:
Mohammad Shahid,
Fraunhofer SCAI, Germany,
Tel: +49 2241 14 2777
E-mail:
Wolfgang Ziegler,
Fraunhofer SCAI, Germany,
Tel: +49 2241 14 2248
E-mail:
