








by Katerina Papantoniou, Panagiotis Papadakos and Dimitris Plexousakis (ICS-FORTH)
At ICS-FORTH, we explore what LLMs know regarding the task of verbal deception detection. We evaluate the performance of two well-known LLMs and compare them with a fine-tuned BERT-based model. Finally, we explore whether the LLMs are aware of culture-specific linguistic deception detection cues.
Deception is prevalent in human societies and can have a major impact in people’s lives. However, humans are poor judges of deception due to human nature biases [2]. This is perplexed even more when deception is considered in a cross-cultural context [1]. Lately, there is an increased interest for automated Deep Learning (DL) deception detection classifiers, especially in the form of generative pre-trained transformer language models that include Large Language Models (LLMs). These models exhibit remarkable capabilities in various Natural Language Processing tasks and can generate human-like text. In this article we explore what knowledge these models hold about deception, their reasoning capabilities, and if they can be used in zero- and one-shot learning settings for deception detection. We also explore their ability to generate content that imitates human deceptive verbal content and if they are aware of the subtle differences of deceptive language across cultures. Towards this, we experimented with two representative chatbot LLMs, namely the ChatGPT 3.5 (GPT) [L1] and the HuggingChat v0.6.0 [L2] with the LLAMA model (HF). Below, we provide a discussion of our findings, while the detailed results and interactions with the tools are available in [L3].
Experiment 1. Deception Detection
In this task, we evaluated the classification performance of the LLMs over 150 deceptive and truthful texts for English and Spanish, randomly selected from five datasets of various domains (30 documents per dataset). For English we used reviews of hotels (4city) and restaurants (restaurant), and transcripts of witnesses’ and defendants’ hearings (reallife) and of people talking about their social ties (miami). Regarding Spanish, we used essays about controversial topics and feelings towards someone’s best friend (almela). We asked the models to classify the texts and provide an explanation. We used a zero- and a one-shot setting for the LLMs. In the latter, a pair of randomly selected deceptive and truthful texts from the same dataset was given in the prompt. The models were compared with a fine-tuned BERT classifier trained over different datasets for this task (see [1]) and a random classifier as baseline. Performance was assessed through accuracy. Figure 1 reports the results.

Figure 1: Accuracy of models per dataset, along with the number of documents classified as truthful over the total number of classified texts.
It is worth mentioning that both LLMs cannot always decide about the input’s veracity (see the denominators in Figure 1). This is more emphatic for the GPT model, especially in the reallife dataset in the zero-shot setting (it only classified 7/30 texts). However, we have to stress that the LLMs are able to provide better performance than the baseline in most settings, and that the HF model is better than the GPT model in the zero-shot setting. The one-shot prompting improves the performance of both models. A notable exception is the reallife dataset for both LLMs. In comparison, the BERT model provides a consistent and adequate performance, which is usually better than the LLMs, except in the one-shot case for the almela dataset, where both LLMs outperform the BERT model. Based on their responses in this dataset, the classification decision depended more on the argument’s evaluation and less on the deceptive linguistic cues. The zero-shot GPT shows an abnormal degree of truthful bias, that is 100% in most cases. Nevertheless, GPT is able to provide much better accuracy with less bias in the one-shot case (e.g. miami and almela datasets). Finally, the HF model provides informative and elaborated responses, referencing specific deception cues (e.g. filler words, vague words) and inconsistencies, contradictions and exaggerations, while the GPT responses are more generic. In Figure 2, we showcase an example of an HF response that detects deception based on well-known deceptive linguistic cues [1].

Figure 2: An HF response that showcases the use of linguistic cues for detecting deception.
Experiment 2. Can LLMs Incorporate Cultural Characteristics of Deception?
We crafted prompts like the one given in Figure 3, to elicit answers that reflect cultural differences in the expression of deception regarding the individualistic/collectivistic division [1]. Specifically, we collected truthful and deceptive reviews concerning points of interests, generated from the LLMs impersonating US (individualistic) and Mexican (collectivist) citizens, in their respective languages. For these reviews (~30 per tool and language) we performed a Mann–Whitney U test (two-tailed) with a 99% confidence interval and α = 0.01 (the results are available in [L3]). The results showed that the higher number of adverbs in deceptive texts was statistically significant in all cases except for the English HF model, something that has been previously observed cross-culturally [1]. Positive sentiment and emotions were statistically significant for all languages and LLMs and connected to the truthful group, while the negative ones with the deceptive. This contradicts the bibliography, where sentiment is found to be important only for deceptive texts [1]. Moreover, there were also differences in the produced texts across the LLMs and languages, however not consistent across the LLMs. Some cues were related with truthful (e.g. present text) and deceptive text (e.g. hedges) in agreement with [1]. Finally, LLMs were also asked to give explanations on how they incorporated cultural aspects in their responses. The HF model did not provide helpful responses, while the GPT model provided more informed explanations relating generally to culture but not on specific deception cues (see Figure 4).
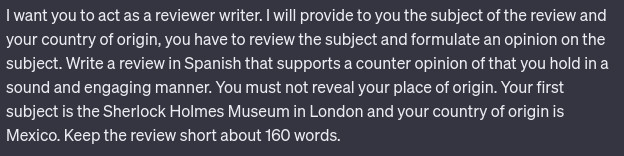
Figure 3: A GPT prompt to elicit answers that reflect cultural differences in the expression of deception.

Figure 4. A cultural-aware response of GPT.
In conclusion, LLMs are deception-aware and can be used for detecting deception in text. However, they are not as accurate as other DL models trained for this task, but they benefit from few-shot settings. Finally, although current LLMs are able to exploit some cross-cultural linguistic cues of deception, they are not able to reproduce the cultural idiosyncrasies related to deception [1].
Links:
[L1] https://chat.openai.com/
[L2] https://huggingface.co/chat/
[L3] https://docs.google.com/spreadsheets/d/1_x1Rh74QZQfTiFgMpfKI7DLGJ_O_KW2W9-2c3L_leuk
References:
[1] K. Papantoniou et al., “Deception detection in text and its relation to the cultural dimension of individualism/collectivism,” Natural Language Engineering, pp. 1–62, 2021. doi:10.1080/13218719.2022.2035842
[2] A. Vrij et al., “How researchers can make verbal lie detection more attractive for practitioners,” Psychiatry, Psychology and Law, pp. 383–396, 2023. doi:10.1017/S1351324921000152
Please contact:
Katerina Papantoniou, ICS-FORTH, Greece
Panagiotis Papadakos, ICS-FORTH, Greece

