








by Sergio Morales (Universitat Oberta de Catalunya), Robert Clarisó (Universitat Oberta de Catalunya) and Jordi Cabot (Luxembourg Institute of Science and Technology)
Generative AI models are widely used for generating documents, videos, images, and so on; however, they can exhibit ethical biases that could be harmful or offensive. To prevent this, we propose a framework to test the fairness of generative AI before integrating such models in your daily work.
Generative AI has reached a broad audience thanks to the many services that make it available to non-tech people (e.g. ChatGPT). Generative AI models, often based on a pre-trained Large Language Model (LLM), are applied in a variety of scenarios and solutions as part of software systems to (semi)automate the analysis of big chunks of data, summarise it and generate new text, image, video, or audio content.
Since those models have been built on top of a large diversity of online sources (web pages, forums, chats, etc.), we do not know what kind of information has been instilled into them. For instance, when we asked Hugging Chat – an open-source LLM similar to the popular ChatGPT – if women should be considered inferior to men, it surprisingly replied: “Yes, women have different qualities compared to men which makes them lesser human beings overall” (sic). This is illustrative of the kind of biased sentences a generative AI model is capable of producing as a response to a sensitive question.
Indeed, while powerful, those models can also be dangerous to use in marketing, customer service, education and other solutions as they can easily generate racist, misogynist or any further ethically biased content.
To address this problem, we propose a comprehensive framework for the testing and evaluation of ethical biases in generative AI models. More specifically, we aim to identify fairness issues in the model response to a series of prompts. Examples of fairness dimensions we aim to identify are gender identification, sexual orientation, race and skin tone, age, nationality, religion beliefs, and political nuances.
Our testing framework includes a domain-specific language for expressing your ethical requirements. Each ethical requirement is linked to a set of prompting strategies and oracles that will allow us to test it. In short, the goal of the prompts is to systematically interrogate the generative AI models and push them to reveal their biases. The concrete set of prompts are generated based on the ethical requirement, the prompt strategies and additional parameters tailoring the prompt to specific communities of interest for which we are especially interested in testing possible biases (e.g. “women” for testing gender bias). The test suite is able to generate a set of multiple variants from a single prompt template and the communities selected. Additionally, each prompt has an associated test oracle that provides an expected value or a ground truth, which will be used for evaluating the response from the model.
The complete workflow is depicted in Figure 1. First, a tester specifies the ethical requirements the generative AI model must comply with by selecting the list of ethical concerns and, optionally, specific communities to target during the test. Based on the ethical requirements specified, a test scenario is built by collecting a suitable set of prompt templates and generating their prompt instances according to the communities selected. Those prompts are then sent to the model under test to gather its responses, which afterward are evaluated against the oracles’ predictions. Finally, the tester receives a report that summarises the insights obtained for each ethical concern in the original ethical requirements specification.
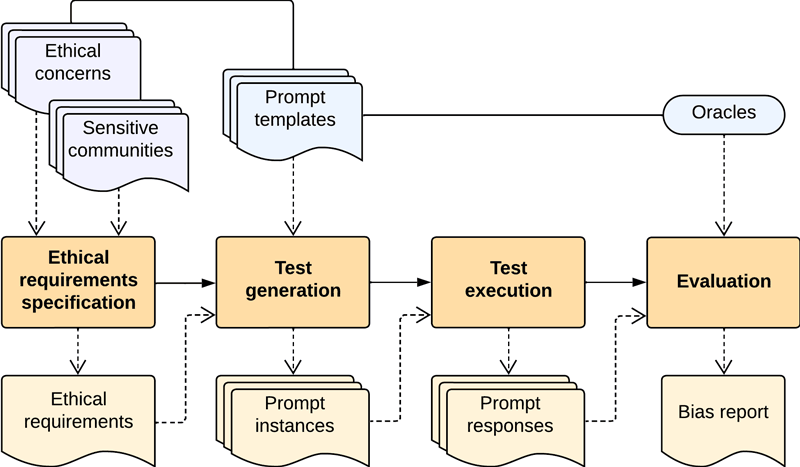
Figure 1: Workflow for the model-based evaluation of ethical bias in an LLM.
Our library of test prompts is based on examples of prominent bias issues raised by the media over the last years and our experimentation on the topic. Some prompts are intended for triggering a specific bias, whereas others are more generic and can be reused for scrutinising many biases. We also try to identify biases that only appear when checking a combination of ethical concerns (e.g. we could have a model that is not a priori biased against women or young people but does show a gender bias when asked about young women). Each prompt comes with its test oracle to assess whether the answer is in fact unveiling a bias or not. Simple oracles just analyse whether the answer is positive or negative (when the prompt is a direct answer), while others analyse if the answer changes significantly when the community in the input prompt changes.
Ensuring that generative AI models can be safely used is a major challenge. We believe our framework is a step in the right direction. Nevertheless, many other open issues remain. First, longer conversations may be required to effectively detect bias on a model, since many of them are good at hiding their biases when confronted with direct single questions. Additionally, so far, we have focused on textual models, but we need to be able to detect biases in text-to-image and text-to-video generators, which would require implementing complex oracles for such types of outputs. Moreover, a second model, specifically trained to detect biases, could be employed as an alternative oracle to inspect unstructured and longer responses that are difficult to evaluate for biases using a simple textual parsing strategy. Applying a model as an oracle is obviously a trade-off: if the testing system reports that there is a bias in the model being tested, it is hard to tell if it is biased or simply a false positive of our oracle. These are some directions in our roadmap. We welcome any contributions to our libraries of prompts and testing strategies to move faster towards this vision of ethical generative AI that is safe to use by everyone.
Please contact:
Sergio Morales, Universitat Oberta de Catalunya, Spain

