








by Jaldert O. Rombouts, Pieter R. Roelfsema and Sander M. Bohte
From the infinite set of routes that you could drive to work, you have probably found a way that gets you there in a reasonable time, dealing with traffic conditions and running minimal risks. Humans are very good at learning such efficient sequences based on very little feedback, but it is unclear how the brain learns to solve such tasks. At CWI, in collaboration with the Netherlands Institute for Neuroscience (NIN), we have developed a biologically realistic neural model that, like animals, can be trained to recall relevant past events and then to perform optimal action sequences, just by rewarding it for correct sequences of actions. The model explains neural activations found in the brains of animals trained on similar tasks.
Neuroscientists have prodded the inner workings of the brain to determine how this vast network of neurons is able to generate rewarding sequences of behaviour, in particular when past information is critical in making the correct decisions. To enable computers to achieve similarly good behaviour, computer scientists have developed algorithmic solutions such as dynamic programming and, more recent, reinforcement learning (Sutton and Barto 1998).
We applied the insights from reinforcement learning to biologically plausible models of neural computation. Concepts from reinforcement learning help resolve the critical credit assignment problem of determining which neurons were useful in obtaining reward, and when they were useful.
Learning to make rewarding eye movements
Animal experiments have shown that in some areas of the brain, neurons become active when a critical cue is shown, and stay active until the relevant decision is made. For example, in a classical experiment by Gnadt & Andersen (1988) a macaque monkey sits in front of a screen with a central cross (Figure 1). The monkey should fixate its eyes on the central cross and, while it is fixating, a cue is briefly flashed to the left or right of the cross. Then, after some delay, the fixation mark disappears. This indicates that the monkey should make an eye movement to where the cue was flashed. The monkey only receives a reward, usually a sip of fruit juice, when it executes the whole task correctly.
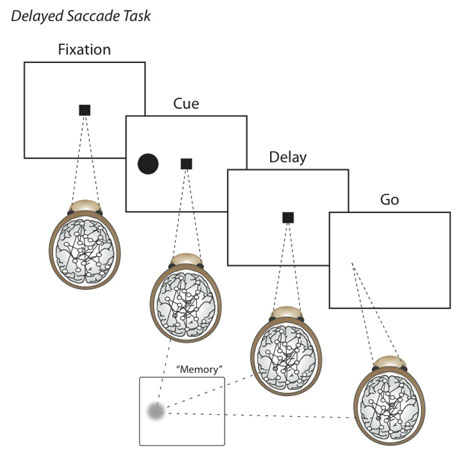
Figure 1: Delayed Saccade Task (Source: CWI)
To solve the task, the monkey must learn to fixate on the correct targets at the correct times, and it must learn to store the location of the flashed cue in working memory, all based on simple reward feedback. The critical finding in these experiments was that, after learning, neurons were found that "remembered" the location of the flashed cue by maintaining persistently elevated activations until the animal had to make the eye movement.
Neural network model
We designed a neural network model that is both biologically plausible and capable of learning complex sequential tasks (Rombouts, Bohte, and Roelfsema 2012). A neural network model is a set of equations that describes the computations in a network of artificial neurons, which is an abstraction of the computations in real neurons. We incorporated three innovations in our neural model:
- Memory neurons that integrate and maintain input activity, mimicking the persistently active neurons found in animal experiments.
- Synaptic tags as a neural substrate for maintaining traces of an input’s past activity, corresponding to eligibility traces in reinforcement learning (Sutton and Barto 1998).
- We let the neural network predict the expected reward for different possible actions at the next time step: action values. At each time step, actions are chosen stochastically, biased towards actions with the highest predicted values.
A plausible learning rule then adjusts the network parameters to have the action values better approximate the amount of reward that is expected for the remainder of the trial. This learning rule is implemented through a combination of feedback activity in the network, and a global reward signal analogous to the function of the neurotransmitter dopamine in the brain.
When this model was applied to complex sequential tasks like the eye-movement task described above, we find that activity in the artificial neurons closely mimics the activity found in real neurons. In the example task, integrating neurons learn to code the cue that indicates the correct action as persistent activity, effectively learning to form a working memory. Thus, the model learns a simple algorithm by trial and error: fixate on the fixation mark, store the location of the flashed cue, and then make an eye-movement towards it when the fixation mark turns off.
The neural network model solves the problem of disambiguating state information: while driving to work, some streets look very similar; remembering the sequence of turns taken provides the information to determine your position. Mathematically, problems where instantaneous state information is aliased with other states are known as non-Markovian. Learning to extract and store information to disambiguate states is a challenge and an open problem. The neural model suggests how brains may solve some of these problems.
Link:
http://homepages.cwi.nl/~rombouts
References:
1. Gnadt, J.W., and R.A. Andersen. 1988. “Memory Related motor planning activity in posterior parietal cortex of macaque.” Experimental brain research 70(1):216–220.
2. Rombouts, J.O., S.M. Bohte, and P.R. Roelfsema. 2012. “Neurally Plausible reinforcement learning of working memory tasks.” to Appear in Advances in Neural Information Processing (NIPS) 25, Lake Tahoe, USA.
3. Sutton, R.S., and A.G. Barto. 1998. Introduction to Reinforcement Learning. MIT Press.
Please contact:
Sander Bohte, Jaldert Rombouts
CWI, The Netherlands
E-mail:
Pieter Roelfsema
Netherlands Institute for Neuroscience (NIN), Amsterdam
E-mail: