









by Dominik Ślęzak, Krzysztof Stencel and Son Nguyen
Large volumes of scientific data require specific storage and indexing solutions to maximize the effectiveness of searches. Semantic indexing algorithms use domain knowledge to group and rank sets of objects of interest, such as publications, scientists, institutes, and scientific concepts. Their implementation is often based on massively parallel solutions employing NoSQL platforms, although different types of semantic processing operations should be scaled with respect to the growing volumes of scientific information using different database methodologies [1].
SONCA (Search based on ONtologies and Compound Analytics) platform is developed at the Faculty of Mathematics, Informatics and Mechanics of the University of Warsaw. It is part of the project ‘Interdisciplinary System for Interactive Scientific and Scientific-Technical Information’ (www.synat.pl). SONCA is an application based on a hybrid database framework, wherein scientific articles are stored and processed in various forms. SONCA is expected to provide interfaces for intelligent algorithms identifying relations between various types of objects [2]. It extends typical functionality of scientific search engines by more accurate identification of relevant documents and more advanced synthesis of information. To achieve this, concurrent processing of documents needs to be coupled with ability to produce collections of new objects using queries specific for analytic database technologies.
SONCA’s architecture comprises four layers (Figure 1). User Interface receives requests in a domain-specific language, rewrites them into the chains of (No)SQL statements executed iteratively against the Semantic Indices and – in some cases – the contents of SoncaDB, and prepares answers in a form of relational, graph or XML structures that can be passed to external reporting and visualization modules.
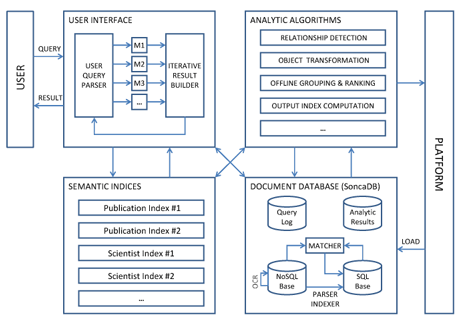
Figure 1: Major layers of SONCA’s architecture.
The Semantic Indices are periodically recomputed by Analytic Algorithms basing on continuously growing contents of SoncaDB. SoncaDB stores articles (and other pieces of information) acquired from external sources in two formats: XML structures extracted for each single document using structural OCR, and subsets of tuples corresponding to documents’ properties, parts, single words and relationships to other objects, populated across data tables in a relational database.
The roles of Analytic Algorithms and the relational subpart of SoncaDB are two examples of SONCA’s innovation. Additional storage of full information about articles in a tabular form gives developers of Analytic Algorithms a choice between relational, structural and mixed methods of data access, data processing, and storage of the obtained outcomes. However, for millions of documents, we should expect billions of rows. Hence, the underlying RDBMS technologies need to be very carefully adjusted.
The increase of volumes of tuples with each document loaded into SONCA is faster than one might expect. Each article yields entities corresponding to its authors, bibliography items, and areas of science related to thematic classifications or tags. These entities are recorded in generic tables as instances of objects (such as scientist, publication, area and so on) with some properties (e.g. scientist’s affiliation or article’s publisher) and links to a document from which they were parsed (including information about the location within a document that a given article was cited, a given concept was described and so on). Instances are grouped into classes corresponding to actual objects of interest (for instance: bibliographic items parsed from several documents may turn out to be the same article) using (No)SQL procedures executed over SoncaDB. Analytic Algorithms are then adding their own tuples corresponding, for instance, to heuristically identified semantic relations between objects that improve the quality of search processes.
Owing to the rapid growth in the volume of data we use technologies based on intelligent software rather than massive hardware. We chose Infobright’s analytic RDBMS engine (www.infobright.com) to handle the relational subpart of SoncaDB because of its performance on machine-generated data originating from sources such as sensor measurements, computer logs or RFID readings. Although SONCA gathers contents created by humans, the way in which they are parsed and extended makes them more similar to machine-generated data sets. We also use carefully selected solutions for other database components such as the structural subpart of SoncaDB (MongoDB is employed here because of its flexibility of enriching objects with new information) and the Semantic Indices (outputs of Analytic Algorithms can be stored in Cassandra, Lucene or PostgreSQL, for example, depending on how they are used by User Interface modules).
The performance and quality tests undertaken so far on over 200K full-content articles resulting in 300M tuples confirm SONCA’s scalability [3], which should be investigated not only by means of data volume but also ease of adding new types of objects that may be of interest for specific groups of users. The relational data model employed within SoncaDB enables smooth extension of the set of supported types of objects with no need to create new tables or attributes. It is also prepared to deal on the same basis with objects acquired at different stages of parsing (e.g. concepts derived from domain ontologies vs. concepts detected as keywords in loaded texts) and with different degrees of information completeness (e.g. fully available articles vs. articles identified as bibliography items elsewhere). However, as already mentioned, the crucial aspect is freedom of choice between different data forms and processing strategies while optimizing Analytic Algorithms, reducing execution time of specific tasks from (hundreds of) hours to (tens of) minutes.
References:
[1] R. Agrawal et al.: The Claremont Report on Database Research. Commun. ACM 52(6), 56-65 (2009).
[2] R. Bembenik et al. (eds.): Intelligent Tools for Building a Scientific Information Platform. Springer (2012).
[3] D. Ślęzak et al.: Semantic Analytics of PubMed Content. In: Proc. of USAB 2011, 63-74.
Please contact:
Dominik Ślęzak
Institute of Mathematics, University of Warsaw, Poland
and Infobright Inc., Canada
E-mail:
