









by Esther Pacitti and Patrick Valduriez
Modern science disciplines such as environmental science and astronomy must deal with overwhelming amounts of experimental data. Such data must be processed (cleaned, transformed, analyzed) in all kinds of ways in order to draw new conclusions and test scientific theories. Despite their differences, certain features are common to scientific data of all disciplines: massive scale; manipulated through large, distributed workflows; complexity with uncertainty in the data values, eg, to reflect data capture or observation; important metadata about experiments and their provenance; and mostly append-only (with rare updates). Furthermore, modern scientific research is highly collaborative, involving scientists from different disciplines (eg biologists, soil scientists, and geologists working on an environmental project), in some cases from different organizations in different countries. Since each discipline or organization tends to produce and manage its own data in specific formats, with its own processes, integrating distributed data and processes gets difficult as the amounts of heterogeneous data grow.
In 2011, to address these challenges, we started Zenith (http://www-sop.inria.fr/teams/zenith/), a joint team between INRIA and University Montpellier 2. Zenith is located at LIRMM in Montpellier, a city that enjoys a very strong position in environmental science with major labs and groups working on related topics such as agronomy, biodiversity, water hazard, land dynamics and biology. We are developing our solutions by working closely with scientific application partners such as CIRAD and INRA in agronomy.
Zenith adopts a hybrid P2P/cloud architecture. P2P naturally supports the collaborative nature of scientific applications, with autonomy and decentralized control. Peers can be the participants or organizations involved in collaboration and may share data and applications while keeping full control over some of their data (a major requirement for our application partners). But for very-large scale data analysis or very large workflow activities, cloud computing is appropriate as it can provide virtually infinite computing, storage and networking resources. Such hybrid architecture also enables the clean integration of the users’ own computational resources with different clouds.
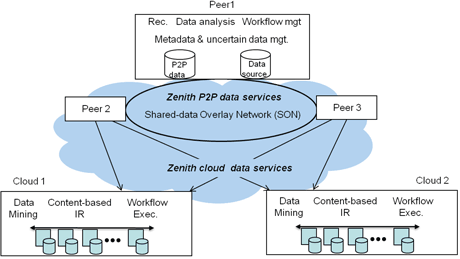
Figure 1: Zenith Hybrid P2P/cloud Architecture
Figure 1 illustrates Zenith’s architecture with P2P data services and cloud data services. We model an online scientific community as a set of peers and relationships between them. The peers have their own data sources. The relationships are between any two or more peers and indicate how the peers and their data sources are related, eg “friendship”, same semantic domain, similar schema. The P2P data services include basic services (metadata and uncertain data management): recommendation, data analysis and workflow management through the Shared-data Overlay Network (SON) middleware. The cloud P2P services include data mining, content-based information retrieval and workflow execution. These services can be accessed through web services, and each peer can use the services of multiple clouds.
Let us illustrate two recent results obtained in this context. The first is the design and implementation of P2Prec (http://www-sop.inria.fr/teams/zenith/p2prec/), a recommendation service for P2P content sharing that exploits users’ social data. In our approach, recommendation is based on explicit personalization, by exploiting the scientists’ social networks, using gossip protocols that scale well. Relevance measures may be expressed based on similarities, users’ confidence, document popularity, rates, etc., and combined to yield different recommendation criteria. With P2Prec, each user can identify data (documents, annotations, datasets, etc.) provided by others and send queries to them. For instance, one may want to know which scientists are expert in a topic and get documents highly rated by them. Or another may look for the best datasets used by others for some experiment. To efficiently disseminate information among peers, we propose new semantic-based gossip protocols. Furthermore, P2Prec has the ability to get reasonable recall with acceptable query processing load and network traffic.
The second result deals with the efficient processing of scientific workflows that are computationally and data-intensive, thus requiring execution in large-scale parallel computers. We propose an algebraic approach (inspired by relational algebra) and a parallel execution model that enable automatic optimization of scientific workflows. With our algebra, data are uniformly represented by relations and workflow activities are mapped to operators that have data aware semantics. Our execution model is based on the concept of activity activation, which enables transparent distribution and parallelization of activities. Using both a real oil exploitation application and synthetic data scenarios, our experiments demonstrate major performance improvements compared to an ad-hoc workflow implementation.
Please contact:
Patrick Valduriez
Inria, France
E-mail:
