









by Marc Spaniol, András Benczúr, Zsolt Viharos and Gerhard Weikum
For decades, compute power and storage have become steadily cheaper, while network speeds, although increasing, have not kept up. The result is that data is becoming increasingly local and thus distributed in nature. It has become necessary to move the software and hardware to where the data resides, and not the reverse. The goal of LAWA is to create a Virtual Web Observatory based on the rich centralized Web repository of the European Archive. The observatory will enable Web-scale analysis of data, will facilitate large-scale studies of Internet content and will add a new dimension to the roadmap of Future Internet Research – it’s about time!
Flagship consumers of extreme large computational problems are the ‘Web 3.0’ applications envisioned for the next 10-year period of Web development: fast and personalized applications accessible from any device, aided by data mining solutions that handle distributed data by cloud computing.
Academically, longitudinal data analytics – the Web of the Past – is challenging and has not received due attention. The sheer size and content of such Web archives render them relevant to analysts within a range of domains. The Internet Archive currently holds more than 150 billion versions of Web pages, captured since 1996. Currently the same coverage cannot be maintained as a few years ago as Web content has become so diverse and dynamic. A high-coverage archive would have to be an order of magnitude larger.
In our applications, the size of the data itself forms the key challenge. Scalability issues arise from two main sources. Certain problems such as Web or log processing are data intensive where reading vast amounts of data itself forms a bottleneck. Others, such as machine learning or network analysis, are computationally intensive as they require complex algorithms run on large data that may not fit into the internal memory of a single machine.
Within the scope of the LAWA project – as part of the Future Internet Research and Experimentation (FIRE) initiative founded by the European Commission – we investigate temporal Web analytics with respect to semantic and scalability issues by creating a Virtual Web Observatory (VWO). The consortium consists of six partners: Max Planck Institute for Informatics (Germany), Hebrew University (Israel), SZTAKI (Hungary), University of Patras (Greece), Internet Memory Foundation (France) formerly called European Archive, and Hanzo Archives Ltd. (UK). The latter two are professional archival organizations.
As a central functionality of the VWO, specific parts of the entire data collection can be defined and selected by the use of machine learning. As an example we may classify different Web domains for spam or genre, quality, objectivity, trustworthiness or personally sensitive social content. The VWO will provide graphical browsing to aid the user in discovering information along with its relationships. Hyperlinks constitute a type of relationship that, when visualized, provides insight into the connection of terms or documents and is useful for determining their information source, quality and trustworthiness. Our main goal is to present relevant interconnections of a large graph with textual information, by visualizing a well-connected small subgraph fitting the information needs of the user.
A Web archive of timestamped versions of Web sites over a long-term time horizon opens up great opportunities for analysts. By detecting named entities in Web pages we raise the entire analytics to a semantic rather than keyword-level. Difficulties here arise from name ambiguities, thus requiring a disambiguation mapping of mentions (noun phrases in the text that can denote one or more entities) onto entities. For example, “Bill Clinton” might be the former US president William Jefferson Clinton, or any other William Clinton contained in Wikipedia. Ambiguity further increases if the text only contains “Clinton” or a phrase like “the US president”. The temporal dimension may further introduce complexity, for example when names of entities have changed over time (eg people getting married or divorced, or organizations that undergo restructuring in their identities).
As part of our research on entity disambiguation we have developed the AIDA system (Accurate Online Disambiguation of Named Entities), which includes an efficient and accurate NED method, suited for online usage. Our approach leverages the YAGO2 knowledge base as an entity catalog and a rich source of relationships among entities. We cast the joint mapping into a graph problem: mentions from the input text and candidate entities define the node set, and we consider weighted edges between mentions and entities, capturing context similarities, and weighted edges among entities, capturing coherence.
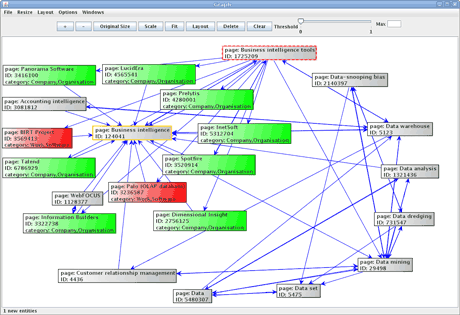
Figure 1: Screenshot of the relevant subgraph visualization demo
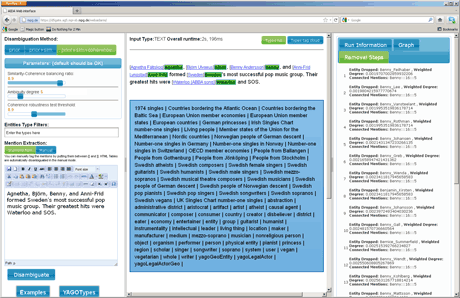
Figure 2: Screenshot of the AIDA user interface in a browser window
Figure 2 shows the user interface of AIDA. The left panel allows the user to select the underlying disambiguation methods and to insert an input text. The panel in the middle shows for each mention (in green) the disambiguated entity, linked with the corresponding Wikipedia articles. In addition, a clickable type cloud allows the user to explore the types of the named entities contained. Finally, the rightmost panel provides statistics about disambiguation process.
In conclusion, supercomputing software architectures will play a key role in scaling data and computational intensive problems in business intelligence, information retrieval and machine learning. In the future we will be identifying new applications such as Web 3.0, and considering the combination of distributed and many-core computing for problems that are both data and computational intensive.
Our work is supported by the 7th Framework IST programme of the European Union through the focused research project (STREP) on Longitudinal Analytics of Web Archive data (LAWA) under contract no. 258105.
Links:
LAWA project website: http://www.lawa-project.eu/
AIDA webinterface: https://d5gate.ag5.mpi-sb.mpg.de/webaida/
YAGO2 webinterface: https://d5gate.ag5.mpi-sb.mpg.de/ webyagospotlx/WebInterface
Visualization demo: http://dms.sztaki.hu/en/letoltes/wimmut-searching-and-navigating-wikipedia
FIRE website: http://cordis.europa.eu/fp7/ict/fire/
Please contact:
Marc Spaniol
Max-Planck-Institute for Informatics, Saarbrücken, Germany
E-mail:
András Benczúr
SZTAKI, Budapest, Hungary
E-mail:
