









by Mircea Lungu, Oscar Nierstrasz and Niko Schwarz
In today’s highly networked world, any researcher can study massive amounts of source code even on inexpensive off-the-shelf hardware. This leads to opportunities for new analyses and tools. The analysis of big software data can confirm the existence of conjectured phenomena, expose patterns in the way a technology is used, and drive programming language research.
The amount and variety of available external information associated with evolving software systems is staggering: data sources include bug reports, mailing list archives, issue trackers, dynamic traces, navigation information extracted from the IDE, and meta-annotations from the versioning system. All these sources of information have a time dimension, which is tracked in versioning control systems.
Software systems, however, do not exist in isolation but co-exist in larger contexts known as software ecosystems. A software ecosystem is a group of software systems that is developed and co-evolves together in the same environment. The usual environments in which ecosystems exist are organizations (companies, research centres, universities) or communities (open source communities, programming language communities). The systems within an ecosystem usually co-evolve, depend on each other, have intersecting sets of developers as authors, and use similar technologies and libraries. Analyzing an entire ecosystem entails dealing with orders of magnitude more data than analyzing a single system. As a result, analysis techniques that work for the individual system no longer apply.
Recently, we have seen the emergence of a new type of large repository of information associated with software systems which can be orders of magnitude larger than an ecosystem: the super-repository. Super-repositories are repositories of project repositories. The existence of super-repositories provides us with an even larger source of information to analyze, exceeding ecosystems again by orders of magnitude.
Research has been empowered by increased network bandwidth and raw computation power to analyze all of these artifacts at possibly massive scales. Therefore it shouldn’t surprise us that current software engineering research uses the new wealth of information to improve the lives of software developers. Analysis of software ecosystems and super-repositories enters the realm of big software data.

Figure 1: A decade of evolution in a subset of the systems in the Gnome ecosystem shows the size of source code monotonically increasing.
In our research, we have been working towards discovering opportunities and challenges associated with big software data. We summarize three of the problems that we are working on, which we believe exemplify distinct directions in the big-software data analysis:
1. Studying Ripple Effects in Software Ecosystems. A change in a software system can propagate to other parts of the system. The same effect can also be observed at the ecosystem level, as we have shown in previous work. By data mining all versions of all the software systems that are available in the SqueakSource ecosystem, we were able to show that due to the tight network of compile-time dependencies between systems (see Figure 2), changes in a project can propagate to many other projects and can impact many developers. There is usually no way for the developers of a library to know which projects are impacted by a change. This presents an opportunity to assist the developer: By keeping track of all dependencies between systems in an ecosystem — an application of Big Software Data — a developer can identify all systems that will be impacted by a change.
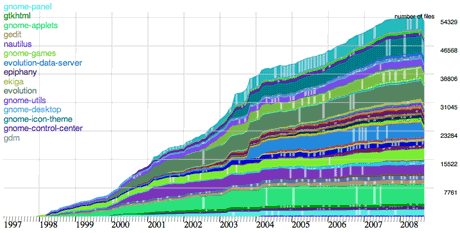
Figure 2: A subset of the software systems in the SqueakSource ecosystem shows a tight network of compile-time dependencies.
2. Code Cloning as a Means of Reuse. We have studied the occurrence of code cloning in Ohloh, a large corpus of Java programs, and in SqueakSource, which tracks versions of almost the entire Squeak Smalltalk ecosystem. We have discovered that reuse by code duplication is very widespread in the Java and Smalltalk worlds - between 14 and 18%. Based on the empirical study of the evolution of clones, the consensus in the software engineering community has shifted from ‘code clones considered harmful’ to ‘code clones considered harmful is harmful’. Indeed, cloning is often a necessary first step towards divergent evolution. It furthermore helps developers deal with problems of code ownership: it is often easier to fork code than to modify it in its project of origin. As a result, current code cloning research is about cloning management and awareness, such as by linking cloned source code snippets to the original site and informing both ends in the event of a change. Big Data means that it is now possible to keep track of all source code in all public repositories everywhere. This opens exciting opportunities to track software clones and try and help developers cope with them.
3. Programming Language Com-parisons. New programming languages and language features are often announced with exaggerated claims of increased productivity. We believe that the analysis of big software data can enable an evidence-based analysis of the various claims regarding programming languages. We are currently running a study in which we compare the use of polymorphism in Java and Smalltalk. This will allow us to understand whether there is any significant difference in how people use object-oriented design in classical static and dynamic languages. The fact that we can run the study on hundreds of Java systems and hundreds of Smalltalk systems allows us to have confidence in the results and their significance.
We believe that we are witnessing the beginning of big software data analysis, a field which will influence both software engineering practice and programming language design. In fact it might be a good place for the two fields to meet.
Link:
http://scg.unibe.ch/bigsoftwaredata
Please contact:
Mircea Lungu, Oscar Nierstrasz,
Niko Schwartz
Unversity of Bern, Switzerland
E-mail:
