









by Gabriel Antoniu, Alexandru Costan, Benoit Da Mota, Bertrand Thirion and Radu Tudoran
Joint genetic and neuroimaging data analysis on large cohorts of subjects is a new approach used to assess and understand the variability that exists between individuals. This approach, which to date is poorly understood, has the potential to open pioneering directions in biology and medicine. As both neuroimaging- and genetic-domain observations include a huge number of variables (of the order of 106), performing statistically rigorous analyses on such Big Data represents a computational challenge that cannot be addressed with conventional computational techniques. In the A-Brain project, researchers from INRIA and Microsoft Research explore cloud computing techniques to address the above computational challenge.
Several brain diseases have a genetic origin, or their occurrence and severity is related to genetic factors. Genetics plays an important role in understanding and predicting responses to treatment for brain diseases like autism, Huntington’s disease and many others. Brain images are now used to understand, model, and quantify various characteristics of the brain. Since they contain useful markers that relate genetics to clinical behaviour and diseases, they are used as an intermediate between the two. Currently, large-scale studies assess the relationships between diseases and genes, typically involving several hundred patients per study.
Imaging genetic studies linking functional MRI data and Single Nucleotide Polyphormisms (SNPs) data may face a dire multiple comparisons issue. In the genome dimension, genotyping DNA chips allow recording of several hundred thousand values per subject, while in the imaging dimension an fMRI volume may contain 100k-1M voxels. Finding the brain and genome regions that may be involved in this link entails a huge number of hypotheses, hence a drastic correction of the statistical significance of pair-wise relationships, which in turn results in a crucial reduction of the sensitivity of statistical procedures that aim to detect the association. It is therefore desirable to set up techniques that are as sensitive as possible to explore where in the brain and where in the genome a significant link can be detected, while correcting for family-wise multiple comparisons (controlling for false positive rate).
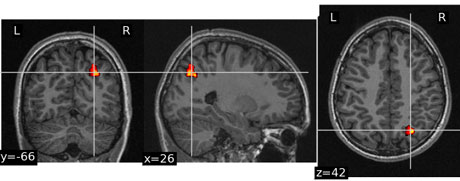
Figure 1: Identifying areas in the human brain (hot colors) in which activation is correlated with a given SNP data, using A-Brain.
In the A-Brain project, researchers of the Parietal and KerData INRIA teams jointly address this computational problem using cloud computing techniques on Microsoft Azure cloud computing environment. The two teams bring their complementary expertise: KerData (Rennes) in the area of scalable cloud data management and Parietal (Saclay) in the field of neuroimaging and genetics data analysis. The Map-Reduce programming model has recently arisen as a very effective approach to develop high-performance applications over very large distributed systems such as grids and now clouds. KerData has recently proposed a set of algorithms for data management, combining versioning with decentralized metadata management to support scalable, efficient, fine-grain access to massive, distributed Binary Large OBjects (BLOBs) under heavy concurrency. The project investigates the benefits of integrating BlobSeer with Microsoft Azure storage services and aims to evaluate the impact of using BlobSeer on Azure with large-scale application experiments such as the genetics-neuroimaging data comparisons addressed by Parietal. The project is supervised by the Joint Inria-Microsoft Research Centre.
Sophisticated techniques are required to perform sensitive analysis on the targeted large datasets. Univariate studies find an SNP and a neuroimaging trait that are significantly correlated (eg the amount of functional activity in a brain region is related to the presence of a minor allele on a gene). In regression studies, some sets of SNPs predict a neuroimaging/behavioural trait (eg a set of SNPs predict a given brain characteristic), while with multivariate studies, an ensemble of genetic traits predict a certain combination of neuroimaging traits. Typically, the data sets involved contain 50K voxels and 500K SNPs. Additionally, in order to obtain results with a high degree of confidence, a number of 10K permutations is required on the initial data, resulting in a total computation of 2.5 × 1014 associations. Several regressions are performed, each giving a set of correlations, and all these intermediate data must be stored in order to compare the values of each simulation and keep that which is most significant. The intermediate data that must be stored can easily reach 1.77 PetaBytes.
Traditional computing has shown its limitations in offering a solution for such a complex problem in the context of Big Data. Performing one experiment to determine if there is a correlation between one brain location and any of the genes on a single core would take about five years. The computational framework, however, can easily be run in parallel and with the emergence of the recent cloud platforms we could perform such computations in a reasonable time (days).
Our goal is to use Microsoft’s Azure cloud to performing such experiments. For this purpose, two million hours per year and 10 TBytes of storage on the Azure platform are available for the duration of the project (three years). In order to execute the complex A-Brain application one needs a parallel programming framework (like MapReduce), supported by a high performance storage backend. We therefore developed TomusBlobs, an optimized storage service for Azure clouds, leveraging the high throughput under heavy concurrency provided by the BlobSeer library developed at KerData. TomusBlobs is a distributed storage system that exposes the local storage from the computation nodes in the cloud as a uniform shared storage to the application. Using this system as a storage backend, we implemented TomusMapReduce, a MapReduce platform for Azure. With these tools we were able to execute the neuro-imaging and genetic application in Azure and to create a demo for it. Preliminary results show that our solution brings substantial benefits to data intensive applications like A-Brain compared to approaches relying on state-of-the-art cloud object storage.
The next step will be to design a performance model for the data management layer, which considers the cloud’s variability and provides some optimized deployment configurations. We are also investigating new techniques to make more efficient correlations between genes and brain characteristics.
Links:
http://www.msr-inria.inria.fr/Projects/a-brain
http://www.irisa.fr/kerdata/
http://parietal.saclay.inria.fr/
http://blobseer.gforge.inria.fr/
Please contact:
Gabriel Antoniu
Inria, France
Tel: +33 2 99 84 72 44
E-mail:
Alexandru Costan
Inria, France
Tel: +33 2 99 84 25 34
E-mail:
Bertrand Thirion
Inria, France
Tel: +33 1 69 08 79 92
E-mail:
