









How can researchers study large-scale cloud platforms and develop innovative software that takes advantage of these infrastructures? Using two experimental testbeds, FutureGrid in the United States and Grid’5000 in France, we study Sky Computing, or the federation of multiple clouds.
The remarkable development of cloud computing in the past few years, and its proven ability to handle web hosting workloads, is prompting researchers to investigate whether clouds are suitable to run large-scale scientific computations. However, performing these studies using available clouds poses significant problems. First, the physical resources are shared with other users, which can interfere with performance evaluations and render experiment repeatability difficult. Second, any research involving modification of the virtualization infrastructure (eg, hypervisor, host operating system, or virtual image repository) is impossible. Finally, conducting experiments with a large number of resources provisioned from a commercial cloud provider incurs high financial cost, and is not always possible due to limits to the maximum number of resources one can use. These problems, which would have been limitations for our sky computing experiments, were avoided by our use of experimental testbeds.
We study sky computing, an emerging computing model where resources from multiple cloud providers are leveraged to create large-scale distributed virtual clusters. These clusters provide resources to execute scientific computations requiring large computational power. Establishing a sky computing system is challenging due to differences among providers in terms of hardware, resource management, and connectivity. Furthermore, scalability, balanced distribution of computation, and measures to recover from faults are essential for applications to achieve good performance.
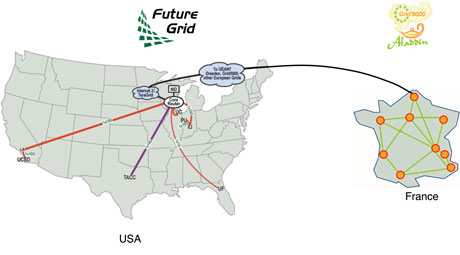
Figure 1: The FutureGrid and Grid’5000 testbeds used for Sky Computing research.
Experimental distributed testbeds offer an excellent infrastructure to carry out our sky computing experiments. We make use of the following two platforms: FutureGrid, a new experimental grid testbed distributed over six sites in the United States, and Grid’5000, an infrastructure for large-scale parallel and distributed computing research composed of nine sites in France. Using the reconfiguration mechanisms provided by these testbeds, we are able to deploy the Nimbus open source cloud toolkit on hundreds of nodes in a matter of minutes. This gives us exclusive access to cloud platforms similar to real-world infrastructures, such as Amazon EC2. Full control of the physical resources and of their software stack guarantees experiment repeatability. Combining two testbeds gives us access to more resources and, more importantly, offers a larger geographical distribution, with network latencies and bandwidth on a par with those found on the Internet. Our project is the first combining these two testbeds, paving the way for further collaboration.
Several open source technologies are integrated to create our sky computing infrastructures. Xen (an open source platform for virtualization) machine virtualization is used to minimize platform (hardware and operating system stack) differences. Nimbus, which provides both an Infrastructure-as-a-Service implementation with EC2/S3 interfaces and higher-level cloud services such as contextualization, is used for resource and virtual machine (VM) management. By deploying Nimbus on FutureGrid and Grid’5000, we provide an identical, Amazon Web Services (AWS)-compatible, interface for requesting virtual resources on these different testbeds, making interoperability possible. We then leverage the contextualization services offered by Nimbus to automatically configure the provisioned virtual machines into a virtual cluster without any manual intervention.
Commercial clouds and scientific testbeds limit the network connectivity of virtual machines making all-to-all communication, required by many scientific applications, impossible. ‘ViNe’, a virtual network based on an IP-overlay, allows us to enable all-to-all communication between virtual machines involved in a virtual cluster spread across multiple clouds. In the context of FutureGrid and Grid’5000, it allows us to connect the two testbeds with minimal intrusion in their security policies. Once the virtual cluster is provisioned, we configure it with Hadoop (open-source software for distributed computing) to provide a platform for parallel fault-tolerant execution of a popular embarrassingly parallel bioinformatics application (BLAST). We further leverage the dynamic cluster extension feature of Hadoop to experiment with the addition of new resources to virtual clusters as they become available. New virtual resources from Grid’5000 and FutureGrid are able to join the virtual cluster while computation is under progress. As resources are added, map and reduce tasks are distributed among these resources, speeding up the computation process. To accelerate the provisioning of additional Hadoop worker virtual machines, we developed an extension to Nimbus taking advantage of Xen copy-on-write image capabilities. This extension decreases the VM instantiation time from several minutes to a few seconds.
Ongoing and future activities involve solving scalability issues in cloud computing infrastructures when requesting resources for large-scale computation, allowing transparent elasticity of sky computing environments, and using live migration technologies to take advantage of dynamicity of resources between multiple cloud platforms.
Our project is a collaboration started in 2010 between the Myriads research team at the IRISA/INRIA Rennes - Bretagne Atlantique laboratory in France, the ACIS laboratory at University of Florida, and the Computation Institute at the Argonne National Laboratory and the University of Chicago.
Links:
http://futuregrid.org/
https://www.grid5000.fr/
http://www.nimbusproject.org/
Please contact:
Pierre Riteau,
Université de Rennes 1, IRISA/INRIA Rennes, France
Tel: +33 2 99 84 22 39
E-mail:
