









by Olof Görnerup and Theodore Vasiloudis (SICS)
In machine learning, similarities and abstractions are fundamental for understanding and efficiently representing data. At SICS Swedish ICT, we have developed a domain-agnostic, data-driven and scalable approach for finding intrinsic similarities and concepts in large datasets. This approach enables us to discover semantic classes in text, musical genres in playlists, the genetic code from biomolecular processes and much more.
What is similarity? This fundamental, almost philosophical, question is seldom asked in machine learning in all but specific contexts. And although similarities are ubiquitous in the field, they are often limited to specific domains or applications; calculated between users to make recommendations, between websites to improve web searches, or between proteins to study diseases, for example.
To enable similarity and concept mining applicable in a broad range of areas, we have proposed a generalisation of the distributional hypothesis commonly used in natural language processing: Firstly, the context of an object (a word, artist or molecule, for instance) is its correlations (co-occurrences, play order, interactions etc) to other objects. Secondly, similar objects have similar contexts. And thirdly, a group of inter-similar objects form an abstraction – a concept.
In this way, we essentially base the notion of similarity on exchangeability. In the case of language, for example, it should be possible to remove a word from a sentence and replace it with a similar one (consequently belonging to the same concept) and the sentence should still make sense. And the same should be true regardless of the dataset and types of objects, whether it is words, items a user interacts with, people in a social network, or something else.
Using these principles, we have developed a method that allows us to find all relevant similarities among a set of objects and their correlations, as well as concepts with respect to these similarities [1,2]. From a bird’s eye view, we achieve this by representing objects and their correlations as a graph, where objects constitute vertices with edges weighed by correlations. We transform this graph to a similarity graph, where edges are instead weighted by similarities. Concepts are then revealed as clusters of objects in the similarity graph.
This approach is scalable and can therefore be applied to very large datasets, such as the whole of Wikipedia or Google Books (4% of all books ever published). It is also completely data-driven and does not require any human-curated data. At the same time, the method is transparent, so we can interpret the similarities and understand their meaning.
We have demonstrated our approach for three different types of data – text, playlist data, and biomolecular process-data – where similarities and concepts correspond to very different things. In the text case (see Figure 1), objects are words, and words that have similar co-occurrence patterns form concepts that correspond to semantic classes, including colours, days of the week, newspapers, vehicles etc. In the playlist case, artists are conceptualised to subgenres and genres. And in the biomolecular case, where codons (triplets of nucleotides in DNA) are related by mutation rates, concepts crystalise as groups of codons that code to the same amino acids, and in effect the method recreates the standard genetic code.
Several improvements and extensions of the method are in the pipeline, including supporting object polysemy (where an object can have several different meanings) and, in particular, mining of higher-order concepts, since an object may also be a concept.
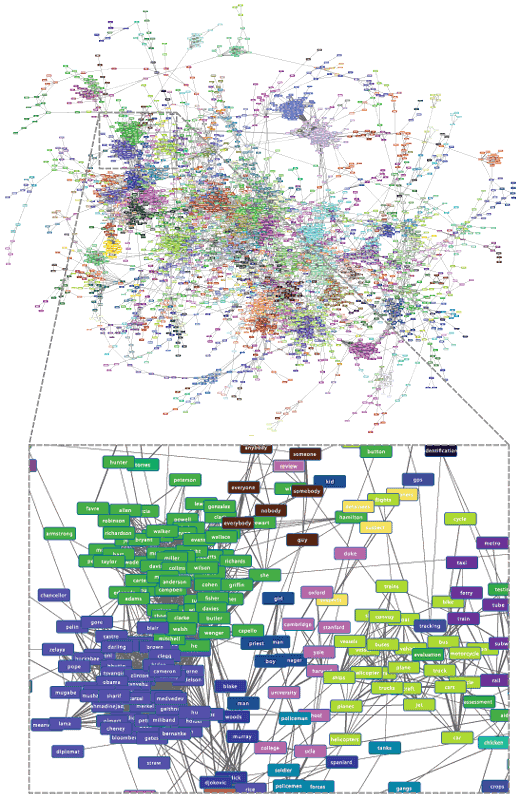
Figure 1: A similarity graph colour coded by concept. The graph was generated using data from the Billion Word corpus. After the similarity transformation was applied to the original correlation graph, community detection was performed to uncover concepts such as “politician”, “university”, or “vehicle” shown in the zoomed in portion.
The code for the algorithm is open-source licensed and available at [L1].
Link:
[L1] https://github.com/sics-dna/concepts
References:
[1] O. Görnerup, D. Gillblad, T. Vasiloudis: “Knowing an object by the company it keeps: A domain-agnostic scheme for similarity discovery”, in ICDM, 2015, pp. 121–130.
[2] O. Görnerup, D. Gillblad, T. Vasiloudis: “Domain-agnostic discovery of similarities and concepts at scale”, in Knowl. Inf. Syst., 2016, pp. 1–30.
Please contact:
Olof Görnerup, SICS, Sweden
+46 70 252 10 62,

